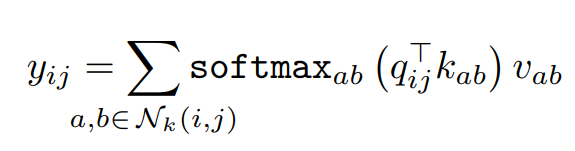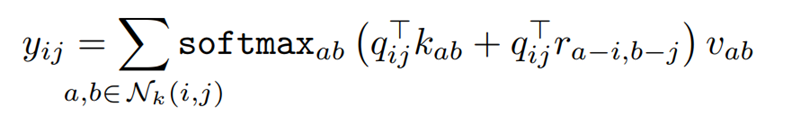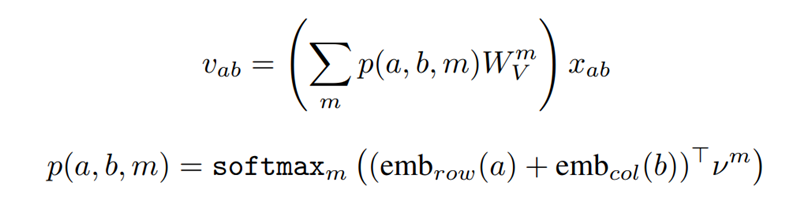paper: Stand-Alone Self-Attention in Visual Models
Abstract
현대 컴퓨터 비전에서 convolution은 fundamental building block으로 역할을 수행해 왔다. 최근 몇몇 연구에서 long range dependency 문제를 해결하기 위해 convolution을 넘어서야 한다는 주장들이 있었다. 이를 위해서 보통 self-attention과 같은 content-based interaction을 증가시키는 방식의 연구들이 진행되어 왔다. 여기서 한가지 의문은 attention이 convolution 위에 쓰이는 것이 아니라 Stand-Alone(독립적으로) 쓰일 수 있느냐이다. 본 논문에서 직접 pure self-attention vision model을 만들고 테스트한 결과 효과적인 Stand-Alone layer로 만들 수 있었다고 했다. Spatial convolution의 모든 요소들을 대체한 stand-alone self-attention은 기존의 attention 모델보다 더 적은 연산, 더 적은 parameter 수를 가지고 더 좋은 성능을 보였다고 한다.
Introduction
Dataset과 computing resource가 풍부해짐에 따라 CNN이 많은 컴퓨터 비전에 주요 backbone으로 쓰여왔고 convolution의 translation equivariance property가 CNN이 주류가 된 핵심이었다. 그러나 CNN은 단순히 주변 값과 고정된 값은 filter의 inner product 계산이어서 large receptive field에 대해 long range interaction이 scale이 커질수록 효율이 떨어진다고 했다.이 long range interaction에 대한 문제는 attention이라는 개념을 사용하여 주로 존재하는 CNN 모델에 global attention layer를 추가함으로써 해결해왔는데 이러한 global하게 적용하는 형태는 input의 모든 spatial location에 적용되므로 original image로부터 많은 downsampling을 해야 하는 small input에만 사용할 수 있는 제한이 있다.본 논문에서는 content-based interaction이 convolution에 추가되는 형태가 아닌 vision model의 primary primitive가 될 수 있는지에 대해 의문을 던졌다. 그래서 마지막 부분에 small input과 large input에 모두 사용할 수 있는 simple local attention layer를 만들었다고 한다. 이 stand-alone attention layer를 기초로 삼아 convolutional baseline보다 뛰어난 성능을 가진 fully attentional vision model도 만들었다고 한다. 더 나아가 stand-alone attention에 대해 이해하기 위해 여러 실험들을 더 진행해 보았다고 한다.
Background
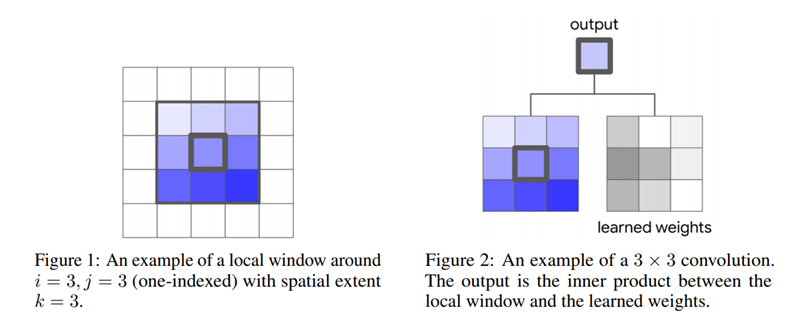
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image1.png]()
Convolutions
Convolution의 연산방식은 위의 그림으로 간단하게 정리할 수 있다. 하나의 pixel을 기준으로 주변에 있는 pixel의 값들과 학습된 filter의 weight를 inner product한 값으로 업데이트 하는 방식의 연산이다. 지금까지 machine learning은 수 많은 분야에서 이 convolution의 영향을 받아서 발전해 왔다. 이러한 convolution을 넘어서 새로운 방식을 찾기 위해 convolution을 재구성하는 여러 연구들도 진행이 되었었다.
Self-Attention
Attention은 variable length source의 information을 content-based summarization 할 수 있는 encoder-decoder의 형태로 적용되어 왔다. Attention은 context에서 중요한 region에 집중하는 법을 학습할 수 있어서 neural transduction model에서 중요한 요소가 되었다.
Representation learning에서 recurrence가 self-attention으로 완전히 대체되어 주요한 메커니즘으로 사용 되었다. Self-attention의 정의는 single context에 적용된 attention이며 self-attention의 long-distance interaction과 parallelizability로 인해 다양한 task에서 SOTA의 성능을 보였다.그리고 몇몇 vision task에도 convolution에 self-attention을 추가하는 방식이 좋은 성능을 보였고 본 논문에서는 convolution을 없애고 전체 network에 local self-attention을 적용함으로써 이러한 방식을 넘어서고자 하였다.
이와 같은 생각이 다른 현존하는 연구 중에 존재했는데 local relation network라는 제목의 논문은 본 논문과 유사한 생각의 흐름에서 새로운 content-based layer를 제시 하였었고 본 연구팀이 제시한 현존하는 vision model에 사용되는 self-attention의 영향력에 집중한 연구와 상호보완적일 것이라 했다.
Attention layer에 관한 연구는 기존의 존재하는 연구들을 재사용하여 간단하게 만드는 것에 초점이 맞춰져 있었는데 본 연구팀은 새로운 attention의 형태를 만들기 위해 이러한 convolution scheme을 버리고 대체하고자 했다.
이제부터 구체적으로 무엇을 했는지에 대해서 살펴보도록 하자. Stand-alone self-attention layer는 convolution과 유사하게 주어진 pixel을 기준으로 주변 local region의 pixel들을 뽑는다. 그리고 이를 memory block이라고 부른다. 이러한 형태의 local attention은 기존의 연구들이 모든 pixel에 대해서 global attention을 수행하여 attention영역을 찾는 방식과 차이가 있다. Global attention은 computationally expensive하기 때문에 크게 downsampling을 하여야만 사용할 수 있었다.
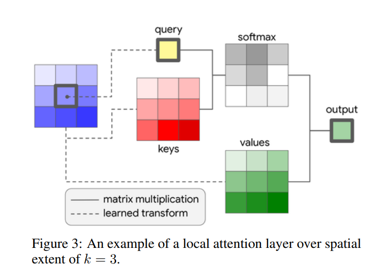
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image2.png]()
이 local attention의 pixel output을 계산하는 single-headed attention은 다음과 같이 계산되며 위의 왼쪽 그림에 표현되어 있다.
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image3.png]()
query, key, value를 각각 q, k, v로 나타내고 각각의 값들은 pixel을 input으로 받아 linear transformation한 것이다.(query는 기준 pixel, key와 value는 주변 pixel) 그리고 softmax를 통해 주변의 모든 pixel에 대해서 계산된 logit을 내보낸다. Local self-attention model은 주변의 pixel의 spatial information을 합친다는 면에서 convolution과 유사하지만 aggregation 결과는 value vector와 weight(contents interaction을 나타낸)의 convex combination이 된다. 이 계산은 모든 pixel에 대해 적용되고 이 multiple attention head는 input의 여러 distinct representation을 학습하는데 쓰인다. 이 연산은 pixel feature를 N개의 channel로 나누어 각각의 그룹에 대해 single-headed attention을 각각 적용하고 output을 concatenate하여 크기를 보존한다. 지금까지 서술한 것에 따르`면 position에 대한 정보가 attention에 들어가 있지 않아서 permutation equivariant해지고 vision task에서의 표현의 다양성을 제한한다. 이미지에서의 pixel의 위치에(absolute position) 대해 sinusoidal embedding을 하는 방식도 있었으나 relative positional embedding으로 진행한 연구결과들이 더 성능이 좋았다. 2D relative position embedding을 통해 attention을 하는 대신에 relative attention을 사용하였다.
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image4.png]()
우선 기준 픽셀과 주변 픽셀 사이의 relative distance에 대해서 정의를 하면 위의 그림과 같이 dimension마다 계산하므로 row offset과 column offset에 대해 2개의 distance를 얻을 수 있다. Dimension이 2이기 때문에 각각 1/2크기의 dimension으로 embedding되며 결과는 concatenate된다. 결국은 relative distance에 대해서 그냥 query와 inner product한단 얘기 같다. 그래서 spatial-relative attention은 아래와 같이 정의된다.
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image5.png]()
기존의 term에 relative distance term을 더한 형태이다. 그러므로 logit은 query에 대해서 주변 pixel들과 거리가 가까운 정도와 어떤 content를 가졌느냐에 따른 similarity를 계산한 것이다. 여기서 self-attention에 infusing 함으로써 self-attention은 convolution과 유사하게 translation equivariance를 가지게 된다.Attention에 사용되는 parameter의 수는 크기와 독립적이지만 convolution은 quadratically 증가한다. 그리고 attention의 computational cost 또한 convolution에 비해 느리게 증가한다. 예를 들면 din = dout = 128일 때, spatial extent가 3인 convolution과 spatial extent가 19인 attention layer의 computational cost가 같았다.
Fully Attentional Vision Models
Local attention layer를 primitive로 사용할 때 어떻게 fully attentional architecture를 사용하는 가가 여기서 의문이다. 본 논문에서는 두 가지 스텝으로 이를 구현했다고 한다.
Replacing Spatial Convolutions
Spatial convolution은 spatial extent가 1보다 큰 convolution이라는 정의를 갖고 있다. 이는 각각의 pixel에 대해 독립적으로 적용되는 fully connected layer인 1 x 1 conv를 제외한 정의이다. 왜냐면 이 1 x 1 conv는 그냥 matrix multiplication이기 때문이다. 본 논문에서는 fully attentional vision model을 만들기 위해 간단한 전략을 탐색해 보았다. 기존의 convolutional architecture를 채택하여 모든 spatial convolution의 요소들을 attention layer로 대체하였다. Downsampling이 필요한 경우, 2 stride로 2 x 2 average pooling이 attention layer 다음에 쓰였다. 이 작업은 ResNet의 family architecture에 적용되었고 ResNet의 core building block은 1 x 1 down-projection conv, 3 x 3 spatial conv, 1 x 1 up-projection conv로 구성되었고 input block 과 output block은 residual connection이 붙어있는데 이게 곧 bottleneck block이다. 이 block은 ResNet에서 여러 번 반복된 형태로 구성되었고 이 block들 내부의 3 x 3 spatial conv를 전부 self-attention layer로 대체한다. 이를 제외한 layer의 수, 어디에 spatial downsampling이 적용되는 지와 같은 모든 다른 구조는 그대로 둔다. 이러한 변환은 매우 간단하지만 suboptimal 일 수 있다. Attention을 핵심 요소로 하여 architecture search와 같은 방법으로 architecture를 찾는다면 더 좋은 architecture를 찾을 수 있을 것이다.
Replacing the Convolutional Stem
CNN의 시작 layer를 stem이라고 부르기도 하는데, 뒤에 있는 layer들이 global object를 찾는데 사용하는 edge와 같은 local feature를 학습하는데 매우 중요한 역할을 한다. Input image가 크기 때문에 stem은 core block과 다르게 downsampling과 같은 lightweight operation에 초점을 맞추기도 한다. 예를 들면 ResNet에서 stem은 stride 2로 7 x 7 conv와 stride 2로 3 x 3 max pooling을 한다.Stem layer에서 pixel의 contents는 RGB이며 각각으로는 별 의미가 없으며 강하게 spatially correlated되어 있다. 이러한 특징이 self-attention 과 같은 content-based 메커니즘으로는 학습하기 어려운 edge detector와 같은 유용한 feature를 학습할 수 있게 한다. 본 논문의 실험에서 self-attention을 stem에 쓰는 것은 ResNet에서 convolution은 stem에 쓰는 것에 비해 더 안 좋은 성능을 보였다고 했다.Convolution에서 distance based weight parametrization은 higher layer에서 필요한edge detector를 비롯한 다른 local feature의 학습을 쉽게 할 수 있게 해주었다. Convolution과 self-attention 사이의 차이를 computation을 증가시키지 않으면서 좁히기 위해 spatially-varying한 linear transformation인 distance based information을 1 x 1 conv를 통해 추가하였다. 새로운 value transformation은 여러 개의 value matrix과 neighborhood pixel과 convex combination을 이루며 아래의 식으로 표현할 수 있다.
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image6.png]()
이러한 위치에 기반한 요소들은 pixel location에 dependent한 scalar weight를 학습한다는 점에서 convolution과 유사하며 이 stem은 이후에 max pooling을 하는 것으로 구성되어있다. 간단하게 말하면 attention receptive field는 max pooling window와 align 되어 있다.
Experiments
ImageNet에서 classification을 COCO dataset에서 object detection을 진행하였다.
Where is stand-alone attention most useful?
Fully attentional model의 인상적인 performance는 stand-alone attention이 vision model에서 대체 가능한 primitive라는 것을 보여줬다. 이 부분에서는 네트워크에서 어떤 부분에서 stand-alone attention이 가장 효과를 나타내는지 보고자 하였다.
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image7.png]()
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image8.png]()
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image9.png]()
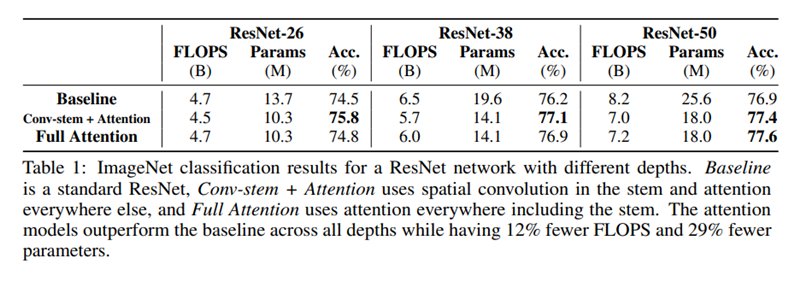
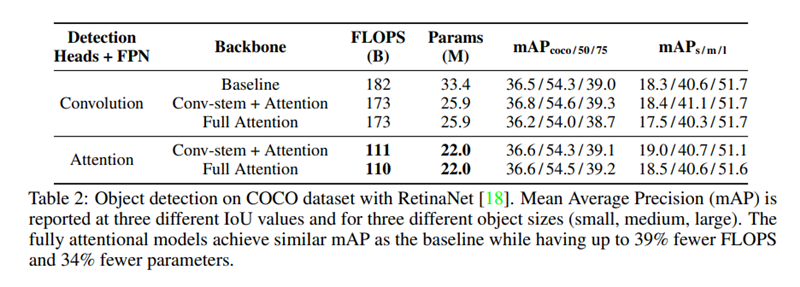
Stem 우선 attention stem와 conv stem을 ResNet에 적용한 것을 비교해 보았다. 모든 다른 spatial conv는 stand-alone attention으로 대체 되었다. Classification에서 conv stem이 attention stem보다 거의 유사하거나 좋은 성능을 보였다. Object detection에서 conv stem이 detection head와 FPN이 conv일 때 더 좋은 성능을 보였지만, 모든 부분들을 fully attentional 하게 해도 비슷한 성능이 나왔다. 이러한 결과는 conv가 여전히 stem에서는 더 효과적이라는 것을 보였다.
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image10.png]()
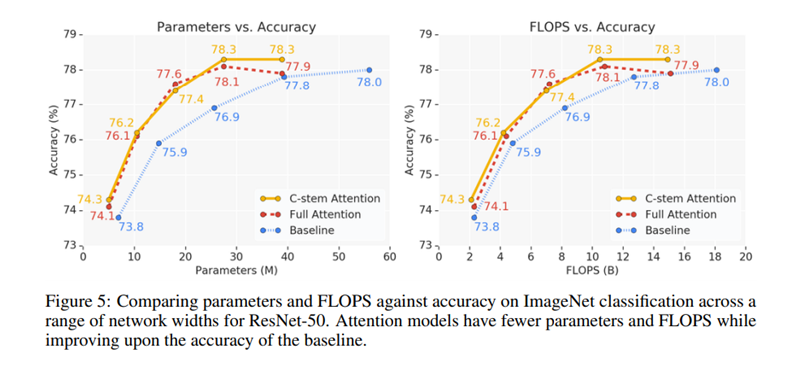
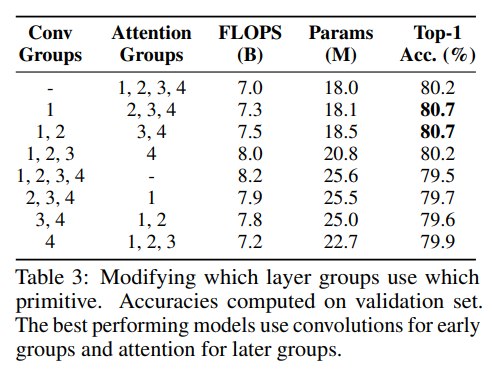
Full Network 다음은 conv와 stand-alone attention을 conv stem을 적용한 ResNet의 다른 layer 그룹에 사용하였다. 가장 좋은 성능을 보인 모델은 conv를 앞부분, attention을 뒷부분에 구성한 것들 이었다. 이 모델들은 fully attentional model과 거의 유사한 FLOPS와 parameter를 가진다. 이와 반대로 attention이 앞부분에 쓰이고 convolution이 뒷부분에 쓰이면 parameter수는 증가하지만 성능은 감소하였다. 이는 conv가 low level feature를 더 잘 찾아내고 stand-alone attention은 global information을 합치는 데에 효과적이라는 것을 나타낸다.이 두 가지 결과는 conv와 stand-alone attention의 장점을 결합해서 architecture design을 해야 한다는 것을 보여준다.
Which components are important in attention?
이 부분에서는 local attention layer의 여러 요소들의 contribution을 이해하고자 ablation study를 하였다. 별다른 언급이 없다면 모든 attention model은 conv stem을 사용하였다.
Effect of spatial extent of self-attention
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image11.png]()
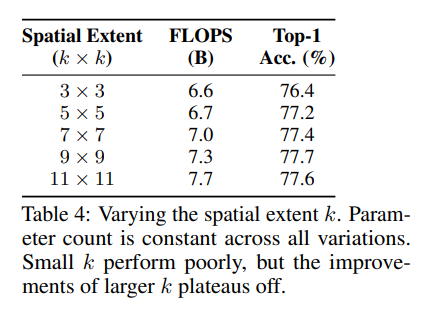
Spatial extent k는 각각의 pixel이 주의를 기울이는 범위를 나타내는 것인데 위의 표는 그 효과를 나타낸다. k=3 과 같이 k가 작다면 performance를 오히려 저하시키고 성능향상은 k=11과 같이 큰 k 주변에서 최고점을 보인다. 최고점의 k값은 feature size나 attention head의 수와 같은 여러 hyperparameter에 따라서 달라진다.
Importance of positional information
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image12.png]()
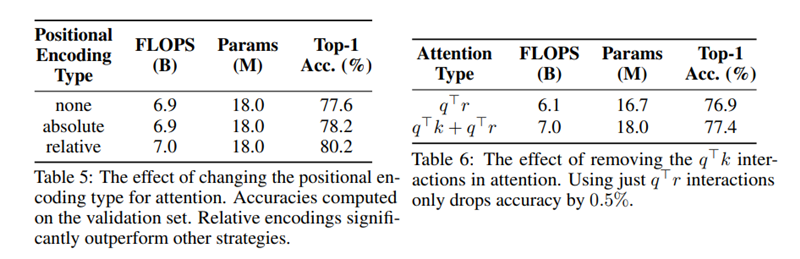
위의 표는 다른 타입의 positional encoding을 때와 positional encoding 하지 않았을 때의 결과를 담았다. 우선 positional encoding을 쓰는 것 자체는 쓰지 않은 것보다 좋은 성능을 보였고 relative position이 absolute position에 비해 더 좋은 성능을 보였다. 또한 content-content interaction을 나타내는(q • k)부분을 없애고 relative interaction만 사용하면 0.5%의 정확도만 떨어진다. Positional information은 중요성은 positional information의 새로운 용도나 parameterization을 찾는 연구를 통해서 attention의 성능을 향상시킬 수 있다는 것을 보여준다.
Importance of spatially-aware attention stem
![Stand-Alone%20Self-Attention%20in%20Visual%20Models%20b8039bb2aba84a3a8af93276adbe856d/image13.png]()
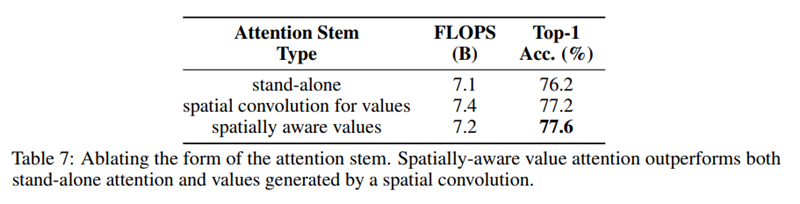
위의 표는 stem에서의 stand-alone attention에서 spatially-aware value를 쓴 것과 쓰지 않은 것을 비교하였고 나아가 value에 spatial convolution을 적용한 것을 비교하였다. Spatially-aware value를 사용한 것이 성능이 제일 좋았고 spatial conv를 적용한 것은 FLOPS수는 높아졌지만 성능은 오히려 약간 떨어졌다. Stem에 쓰이는 spatially-aware attention과 network안에서 쓰이는 attention을 하나로 통합하는 연구도 이루어 질 수 있을 거라 하였다.
Discussion
본 논문에서는 content-based interaction이 vision model의 primary primitive의 역할을 할 수 있다는 것을 확인하였다. Stand-alone local self-attention layer로만 이루어진 fully attentional network가 적은 parameter수와 FLOPS로 더 좋은 성능을 낸다는 것도 보였다. 더 나아가 attention은 특히 후반부의 layer에서 효과적이라는 것도 보였다.또한 이 network의 성능 향상의 여지도 찾았다. 첫째는 우선 attention 메커니즘은 geometry를 더 잘 잡아내는 방법을 개발함으로써 향상시킬 수 있고 둘째로, 단순히 기존의 모델의 변형이 아닌 architecture search를 이용해 더 나은 architecture를 찾아서 향상시킬 수 있고 마지막으로, 앞부분의 layer에서 효과를 보여서 low level feature를 잘 잡아낼 수 있는 새로운 attention의 형태에 대해 추가적인 연구를 할 수 있다고 했다. Attention based architecture에서 training 효율과 computation에 관한 수요가 기존의 convolution에 맞춰져 있어서 결과 network가 실제로는 느리다. 이러한 차이가 생기는 이유는 다양한 하드웨어 가속기에 쓸 수 있는 optimize된 kernel이 없기 때문이다. 이 분야에서 attention이 성공적인 방법으로 여겨져서 가속화 프로그램들이 생긴다면 training과 inference의 실제 실행속도도 빨라질 것이다. 이 연구에서는 vision task에서 content-based interaction의 장점에만 초점을 맞췄는데 나중에 convolution과 self-attention의 각각의 고유한 장점을 결합하고 싶다고 했다. 이러한 content-based interaction의 성공으로부터 다른 cnn을 사용했던 vision task에 attention이 어떻게 적용될 수 있는지 추가적인 연구가 진행되는 것을 기대할 수 있었다.