paper: Robust Place Recoginition using an Imaging Lidar
Introduction

이 논문은 3D point cloud로부터 얻은 intensity range image를 이용해 robust, real-time place recognition을 했다고 한다. ORB feature를 bag-of-word에 저장하고 이를 place recognition에 사용한다. BoW에 query를 보내 얻은 결과의 validation을 위해 visual feature desciptor matching을 하는데 여기서 PnP를 사용해 outlier rejection을 한다. 이런식으로 카메라와 라이다 방식을 둘다 활용하여 온전하게 rotation-invariant한 place recognition을 할 수 있다고 한다.
이 논문의 main contribution은 다음과 같다.
- 최초로 intensity range image를 활용하여 real-time robust place recognition방법을 찾았다.
- Sensor의 pose에 invariant한 방법을 제안하였다.
- 다른 scale, platform, environment의 data에서 검증하여 extensive하게 검증되었다.
Methodology

전체적인 과정은 다음과 같다. Point cloud로부터 intensity image를 얻고 ORB feature를 추출하여 DBoW에 query하여 유사한 이미지를 추출한다. 그 후 feature matching을 하고 PnP RANSAC을 사용해 outlier rejection을 해서 validation을 한다.
Intensity Image
우선 point cloud $\mathbb{P}$를 cylindrical intensity image $\mathbb{I}$에 projection한다. 각 pixel의 값은 intensity이며 image processing에서 grayscale에서 사용하는 값의 범위와 같은 0~255 사이의 값이 되도록 normalization을 해준다. valid point가 없는 pixel의 경우 0을 부여한다.
Feature Extraction
이 논문에서는 다양한 scenario에 적용할 수 있도록 sensor의 orientation이 심하게 변한다고 가정하여 연구를 진행했다고 한다. 그래서 rotation invariant한 ORB(Oriented-FAST Rotated BRIEF) feature가 적합하다고 생각해서 이를 선택했다고 한다. Sensor의 움직임으로 인해 object의 scale은 sensor와 object사이의 scale이 되며 object의 orientation은 sensor orientation을 기준으로 한다. 다양한 scale과 orientation에 robust하게 feature extraction을 하기 위해서 각각 1.2의 비율로 8단계로 down sampling을 하여 다른 resolution을 가진 8개의 intensity image를 얻는다. ORB feature는 FAST algorithm으로 찾은 후에 BRIEF를 사용하여 corner feature를 descriptor로 변환한다. 그 결과로 $N_{bow}$개의 ORB feature descriptor를 얻게 되고 이를 $\mathbb{O}$라 한다.
DBoW Query
이 논문에서는 ORB feature descriptor $\mathbb{O}$를 visual vocabulary를 사용해 bag-of-word vector로 변환하며 이는 DBoW database를 만드는데 사용된다. 각각의 bag-of-word vector가 point cloud를 나타내는 것이다. 그래서 새로은 bag-of-word vector가 들어오게 되면 database에서 query하여 database에 존재하는 vector들과의 similarity를 L1 distance를 이용해 구한다. 만약 similarity가 $\lambda_{bow}$보다 높다면 potential revisit candidate를 찾았다고 본다. 그리고 새로운 bag-of-words vector는 query후에 database에 추가된다.
Feature Matching
일반적으로 DBoW에 query를 날려 얻는 candidate는 많은 false detection을 포함한다. Detection을 validate하기 위해서 두 frame의 $\mathbb{O}_i,\mathbb{O}_j$를 사용해 matching을 한다. 이 descriptor matching은 computationally expensive하고 false match가 많이 발생하기 때문에 corner score의 내림차순으로 $\mathbb{O}_i$에 순위를 매긴다. $N_s$개의 largest corner score를 가지는 descriptor를 선택하고 이를 $O_i$라 하고 각각 $O_i$와의 best match를 $\mathbb{O}_j$에서 찾는다. 두 descriptor 사이의 distance는 Hamming distance를 사용해 구한다. 이 Hamming distance의 오름차순으로 matched descriptor들의 순위를 또 매긴다. 최종적으로 false match를 걸러내기 위해 $\lambda_h$이하의 Hamming distance를 가지는 match들만 다음단계에 사용한다. 여기서 $\lambda_h$는 smallest Hamming distance의 2배로 잡았다. 여기서 matched descriptor는 $O_i, O_j$로 표기한다. 그러나 이 과정 이후에도 여전히 false positive match들이 많이 존재하며 충분히 작은 $\lambda_h$를 사용했음에도 불구하고 많은 true positive match들이 reject 되었다고 한다. 그래서 $N_m$개 이상의 match가 남아있는 상황이라면 이후에 PnP RANSAC을 사용해 outlier rejection을 한번 더 해준다.
PnP RANSAC
이전 단계에서 얻은 candiate를 validate하기 위해서 PnP 문제를 푼다. PnP 문제는 $O_i$에 존재하는 feature들의 3D Euclidean position을 알고 있고 2D image 상에서의 $O_j$에 존재하는 feature들의 position을 알기 때문에 이 correspondence들 사이의 reprojection error를 minimize하는 문제이다. 그러나 PnP는 false match에 취약하기 때문에 robustness를 위해 RANSAC을 사용하여 outlier rejection을 했다. Inlier의 수가 $N_p$ 이상 이라면 이 candidate를 correct detection이라고 판단하며 PnP의 결과로 나온 relative pose를 이용해 frame-to-frame registration에 활용할 수 있다고 한다.
Experiments
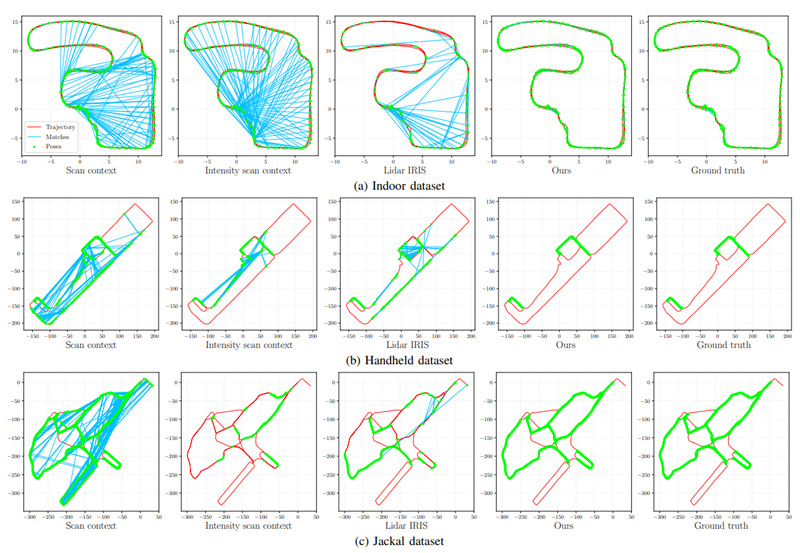
precision과 recall 모두 압도적인 성능을 보였다.

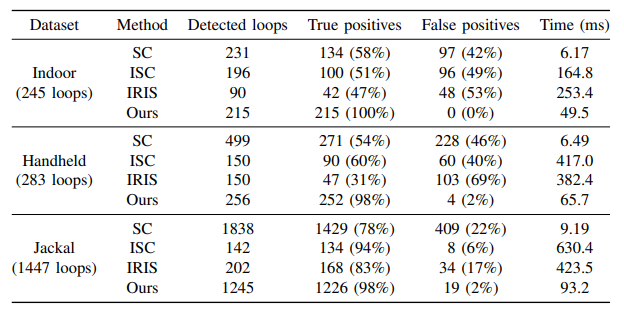
SLAM 전체 과정에서 Loop-clousure detection에 소모되는 시간이 꽤 되는데 사실 마지막 registration이 지금까지 돌려본 경험 상으로는 i7 10세대 CPU에서 voxel size를 0.2m정도로 해도 거의 1000ms~2000ms 정도 소모되었던 것으로 기억하는데(물론 빨리 수렴하면 더 빠르긴 했지만…) 정확한 relative pose를 추정을 하지 않으면 의미가 없기 때문에 시간 소모는 어느정도 이하기만 하면 크게 의미는 없는 것 같다. Scan Context에 비해서 확실히 느리긴 하지만 Scan Context의 false positive 비중이 거의 사용 불가한 수준인 것을 감안하고 후의 registration 시간까지 합치면 별 차이가 없는 수준이기에 논문대로의 recall과 precision이 나와준다면 확실하게 메리트가 있는 방법인것 같다.
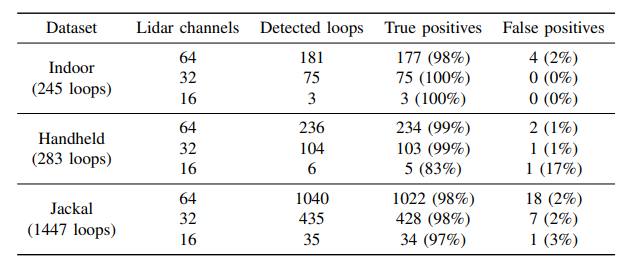
64채널까지는 어느정도 성능이 나오는 것을 볼 수 있지만 32채널이나 16채널의 성능은 좀 많이 떨어졌다.
총평
camera와 lidar-based 방법들을 결합하였다고 주장하지만 사실 그냥 lidar data를 range image로 바꿔서 camera-based 돌린 방법이지 않나 싶긴하나 어쨌든 결과는 상당히 좋아서 눈여겨 볼만하다고 생각한다. Poincloud Descriptor도 BoW에 같이 포함해서 시도할만한 방법들도 떠올려 보면 좋을 것 같다.
PnP의 결과로 나온 relative pose를 SLAM에 사용할 수 있을거라 얘기했는데 이에 관한 결과도 첨부 되었으면 좋을것 같은데 이게 없어서 직접 테스트를 해봐야 할 것 같다.
그리고 motion distortion을 배제하기 위해서 여기서 취득한 데이터는 매우 천천히 움직였다고 하는데 구체적으로 이런 motion distortion의 영향이 어느 정도인지 이를 해결하기 위해서 range image 변환할때 어떤 처리를 할 수 있을지도 고민해 볼만한 것 같다.
그리고 vertical resolution이 일정하지 않을때 이 논문의 방식대로면 sensor의 pose에 따라서 같은 물체도 형태가 달라질 소지가 충분히 있는데 이를 좀 반영할 수 있는 range image building 방법이 필요할 것 같다.