PointNet
paper: PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
code: https://github.com/charlesq34/pointnet
point cloud는 geometric data 구조중에서 중요한 type이지만 unordered라는 특성 때문에(좌표순처럼 sorting이 된것이 아닌 measurement 순서) image처럼 사용하기 위해서 기존에는 3D voxel grid형태의 data로 바꿔서 사용해왔다. 이러한 과정으로 인해 data 본래의 특성이 일부 소실될 가능성이 있어서 PointNet은 permutational invariance한 neural network를 제안해 point cloud를 input으로 직접 사용할 수 있도록 하였다. classification, segmentation 같이 여러 task에서도 좋은 성능을 보였다고 한다. 그리고 왜 이 network가 perturbation과 corruption에도 강건한지에 대한 ablation study도 진행하였다.
- Method
- Properties of Point Sets in $\mathbb{R}^n$
- Unordered: image에서의 pixel array와 다르게 point set은 특정한 order가 존재하지 않으므로 크기가 $N$인 point set이 있다면 $N!$ permutation에 대해서 모두 같은 결과가 나오도록 network를 구성해야 한다.
- Interaction among points: point들은 주변 point들과 묶여서 meaningful한 subset을 이루므로 network model이 주변 point들의 local structure, combinatorial interaction을 학습할 수 있어야 한다.
- Invariance under transformations: 단순히 rotating, translating된 point에 대해서 결과가 달라져서는 안된다.
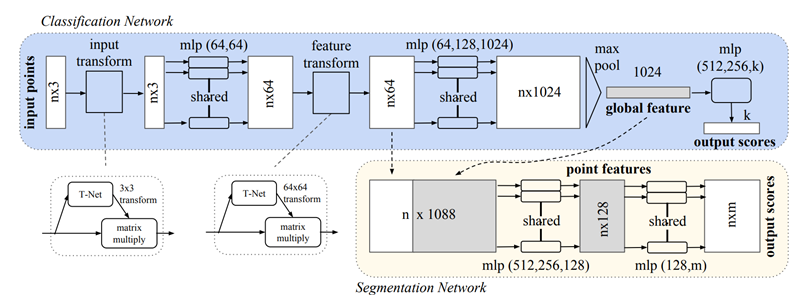
PointNet Architecture
전체 network구조는 위의 그림과 같으며 크게 3개의 key module로 이루어져 있다.
모든 point의 information을 통합하는 symmetric function으로 사용되는 max pooling layer, local & global infomation을 통합하는 모듈, input point와 feature에 대해서 align을 하는 joint alignment network.
Symmetry Function for Unordered Input
model을 input의 permutation에 대해 invariant하게 하려면 input을 정해진 order로 sorting하는 방법, input을 sequence로 생각해서 RNN에 학습하며 모든 permutation을 고려하도록 augmentation을 해서 학습하는 방법, information을 통합하기 위해서 simple symmetric function을 사용하는 방법이 있다.
첫번째 방법이 쉬워보이지만 high dimensional space에서는 ordering이 perturbation에 대해서 stable하지 않으며 두번째 방법은 결국 RNN이 input order에 invariant하도록 학습이 될거라는 기대하에 제안된 아이디어지만 OrderMatters라는 논문에 실제로 이 order를 무시를 할 수 없다는 것을 보였는데 결국은 RNN이 작은 수의 input에 대해서는 어느정도 robustness를 보여줄 수 있지만 point cloud처럼 수만개의 data에 대해서는 좋은 성능을 보여줄수 없었다. 그래서 본 논문에서는 symmetric function을 사용하였다.
본 논문에서 찾고자 하는 symmetric function을 general하게 나타내면 다음과 같다.
\[f(\{x_1,...,x_n)\}\approx g(h(x_1),...,h(x_n)) \\ f:2^{\mathbb{R}^N} \rightarrow \mathbb{R},\ h:\mathbb{R}^N\rightarrow \mathbb{R}^K,\ g:\mathbb{R}^K\times\cdots\times\mathbb{R}^K\rightarrow\mathbb{R}\]실제로 위의 수식을 통해 본 논문에서 사용하고자 하는 module을 설명하면 매우 간단하다. 여기서 $h$가 multi-layer perceptron network, $g$가 max pooling function이 된다. $h$의 collection의 max pooling이 point set의 특징을 잘 나타내도록 학습하는 것이다.
Local and Global Information Aggregation
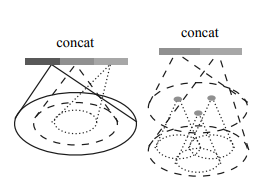
Segmentation 문제에서는 point의 local과 global 정보의 combination이 필요하다. 그래서 이 모듈을 도입하였는데 위의 그림에도 나와있듯이 중간 layer에 있는 local feature에 point마다 global feature를 그저 concatenate함으로써
Joint Alignment Network
point cloud에 transformation이 일어나도 target task의 결과가 달라져서는 안 되는데 이를 위해서 T-net이라는 mini network를 사용해 affine transformation matrix를 predict하고 이 transformation을 input point에 적용하는 것으로 이 문제를 해결하였다고 한다. 이 T-net의 구조는 max pooling과 fc layer로 이루어져있고 feature extraction network와 닮아있다. 그리고 이 alignment를 euclidean space, feature space에 둘 다 적용한다. 근데 feature space에서의 transformation은 feature의 dimension이 커지면 optimization이 매우 어려워지므로 orthogonal transformation이 input의 information을 잘 보존하므로 이 방향으로 학습하기 위해 feature transformation matrix가 orthogonal matrix에 가까워지도록 loss에 다음과 같은 regularization term을 추가한다.
\[L_{reg}=||I-AA^T||^2_F\]여기서 $A$가 T-net으로 predict하는 feature alignment matrix이다.
- Theoretical Analysis
Universal approximation
이 부분은 논문에서 제시한 neural nwtwork의 continuous set function에 대한 approximation ability에 대해서 알아보는 부분이다. 우선 직관적으로 set function의 continuity로 인해 작은 perturbation은 function value에 큰 변화를 일으키지 않을 것이라 생각할 수 있다. 이를 수식으로 표현하면
Theorem 1. 만약 $f:X\rightarrow\mathbb{R}$이 Hausdorff distance $d_H(\cdot,\cdot)$에 대해 continuous set function이면 $S\in X$에 대해 $\forall\epsilon>0$ , $\exists$ continuous function $h$, symmetric function $g(x_1,…,x_n)=\gamma\circ\max$ 이다.
\[|f(S)-\gamma(\max\limits_{x_i\in S}\{h(x_i)\})|<\epsilon\]여기서 max는 vector의 element-wise maximum 이다. 결국에는 완벽한 continuous set function $f$와 bounded error를 가진 function을 neural network를 통해서 구할 수 있다는 말이다.
Bottleneck dimension and stability
PointNet의 expressiveness는 max pooling layer의 dimension $K$에 크게 영향을 받는다고 한다. 그래서 이론적으로 model의 stability에 영향을 끼치는 특징들에 대해서 분석을 했다고 한다.
Thoerem 2. 만약 $\mathbb{u}:X\rightarrow\mathbb{R}^K, \mathbb{u}=\max\limits_{x_i\in S}{h(x_i)}, f=\gamma\circ\mathbb{u}$라 하면
\[(a)\ \forall S,\exists C_S,N_S\subseteq X,f(T)=f(S)\ ifC_S\subseteq T\subseteq N_S \\ (b)\ |C_S|\leq K\](a)는 $f(S)$에 실제로 영향을 주는 point들 $C_s$만 보존되면 $f(S)$가 $N_S$까지 noise가 추가되어도 변하지 않는다는 의미로 corruption에도 robust하다는 것을 보여주는 것이고 (b)는 $f(S)$를 결정하는 ciritical point set $C_S$가 max pooling output dimension $K$에 의해 bounded된다는 것이므로 $K$를 bottleneck dimenstion이라고 부른다고 한다.
이 두 theorem들을 통해 model이 perturbation, corruption에 어느정도 robust하다는 것을 보였으며 이를 통해 pointnet이 sparse한 key point의 set으로 shape를 summarize하는 것을 잘 학습하였다는 것을 직관적으로 알 수 있다.
- Properties of Point Sets in $\mathbb{R}^n$
PointNet++
paper: PointNet++: Deep Hierarchical Feature Leaning on Point Sets in a Metric Space
code: https://github.com/charlesq34/pointnet2
PointNet++는 PointNet 저자의 후속 논문으로 PointNet이 point가 존재하는 metric space의 정보를 local sturcture를 학습할 때 반영하지 못한 점을 보완하여 작은 pattern에 대한 인식 능력이나 complex scene에 대한 generalizability를 높이고자 하였다. 이 논문에서는 이를 input point set을 nested partitioning을 하고 이 구조에 PointNet을 recursive하게 적용하는 hierarchical neural network를 도입하여 해결하였다. metric space의 distance 정보를 활용했기에 이 논문에서는 contextual scaling이 향상된 local feature를 학습할 수 있다고 하며 density에 invariant하도록 하기 위해 여러 scale의 feature들을 adaptive하게 결합하기 위해서 새로운 set learning layer도 제안하였다고 한다.
이 논문의 주요한 contribution은 다음과 같다.
- 여러 scale에서의 neighborboods를 이용해 robustnest와 detail한 학습을 이뤄냈다고 한다.
- Training과정에서 random input dropout을 통해 network가 adaptive하게 다양한 scale에서 얻은 pattern에 weight을 주고 결합하도록 학습시켰다.
- Method
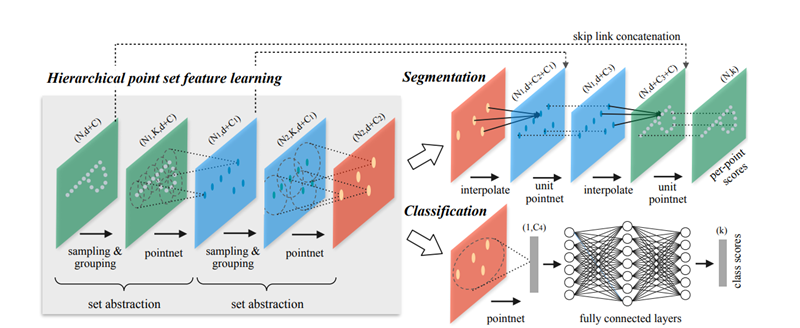
Hierarchical Point Set Feature Learning
PointNet은 전체 point set을 통합하기 위해서 한번만 max pooling을 했던 반면 이 논문에서는 point를 hierarchical하게 grouping을 하고 이 hierarchy에 따라서 점점 넓은 영역의 feature를 추상화한다.
Hierarchical structure는 여러개의 set abstraction 층으로 구성되어 있고 각각의 층은 세개의 key layer로 구성된다. 그리고 set abstraction의 각 level은 $N\times(d+C)$의 matrix를 input으로 한다. 여기서 $d$는 point가 존재하는 space의 coordinate의 dimension, $C$는 feature space의 dimension이다. output으로는 $N^{\prime}\times(d+C^{\prime})$의 matrix 형태를 가진다.
Sampling layer
말그대로 point를 sampling하는 layer로 farthest point sampling(FPS)를 사용해 최대한 point들이 서로 멀리 떨어져 있도록 뽑는다. FPS를 사용하면 전체 point set에서 골고루 뽑게 되어서 receptive field를 만들어내는 효과도 보인다.
Grouping layer
Input data는 $N\times(d+C)$형태의 data와 sampling한 point의 수가 $N^\prime$이므로 sampling된 point의 set인 $N^\prime\times d$ 형태의 data이며 output data의 형태는 sampled point의 특정 distance 이내의 $K$개의 주변 point로 group을 만들어 $N^\prime\times K\times(d+C)$가 되고 $K$는 group마다 상이할 수 있다.
PointNet layer
Input data는 $N^\prime\times K\times(d+C)$형태의 data가 들어오고 각각의 centroid에 대해서 feature를 구해 $N^\prime \times(d+C^\prime)$형태의 output data를 얻을 수 있다. 이를 위해서 PointNet을 사용하였으며 centroid point를 중심으로 coordinate를 옮긴 후에 network에 input으로 넣어준다. 이렇게 relative coordinate를 사용해 local region에서 point들간의 관계를 학습하고자 하였다.
Robust Feature Learning under Non-Uniform Sampling Density
![PointNet,%20PointNet++%2098674300965e4c28a8d8ec021d0ae52b/Untitled%202.png]()
Point set의 feature를 학습하는데에 있어서 멀리있는 물체와 가까이 있는 물체의 point의 density가 다른 문제(non uniformity)는 매우 중요한 문제다. 이상적으로는 point가 dense한 region에서는 매우 상세한 feature들을 학습할 수 있지만 sparse한 영역에서는 sampling 된 point가 부족하다보니 local pattern 자체가 corrupt 되어있다. 이런 경우에는 보다 넓은 영역에서의 pattern을 찾아봐야하는데 이렇게 density에 따라서 adaptive하게 학습하게 하기 위한 point layer를 도입하였다. 이렇게 density adaptive PointNet layer를 가진 hierarchical network를 PointNet++라고 부른다고 한다.
이 논문에서는 grouping하는 local region의 관점에서와 여러 scale에서 온 feature를 합치는 관점에서 두 가지 형태의 density adaptive layer를 제안하였다.
Multi-scale grouping (MSG)
MSG에서는 여러 scale의 pattern을 얻기 위해서 위의 왼쪽 그림과 같이 다양한 크기로 grouping하는 layer를 거친 이후에 각 scale의 feature를 뽑기 위해 PointNet을 적용하였고 그 후에 concatenate한다. 그리고 이 multi-scale feature를 잘 학습하기 위해서 random input dropout을 사용해 다양한 density와 nonuniformity한 데이터에 대해서도 학습하였다.
Multi-resolution grouping (MRG)
MSG는 모든 centroid point에 대해서 넒은 영역의 neighborhood를 input으로 한PointNet을 사용하기 때문에 computationally expensive하다. 그래서 computation cost를 낮추면서 adaptive하게 information을 합치는 성능을 보존하기 위해 MRG를 제안했다. 위의 오른쪽 그림과 같이 level $L_i$ feature의 형태가 두 개의 vector가 concatenate된 것을 볼 수 있다. 여기서 왼쪽 vector는 이전 level $L_{i-1}$에서 온 feature들을 summarize한다는데 이 부분은 어떻게 하는지는 코드에도 없고 나와있지를 않아서 모르겠다 아마 단순히 concatenate한 것이 아닌가 싶은 생각이 든다. 그리고 오른쪽 vector는 해당 local region내에 있는 모든 point에 대해서 PointNet을 사용해 feature를 뽑은 것이다. 그래서 local region의 density가 낮으면 앞의 vector가 뒤의 vector에 비해 신뢰도가 낮아지므로 뒤의 vector에 weight를 더 주고 반대의 경우는 앞의 vector에 weight를 더 준다고 한다.
MRG가 MSG에 비해서 낮은 level에서 large scale의 neighborhood에 대해서 feature extraction을 할때 특히 computationally efficient하다고 한다.
Point Feature Propagation for Set Segmentation
Set abtraction layer에서 원래 point가 subsample 되는데 segmentation task에서는 모든 point의 label을 얻어야 하기 때문에 이를 위해서는 그냥 모든 point를 사용하는 방법과 subsample된 point에서 original point들로 feature를 propagation을 하는 방법이 있다고 한다. 전자는 당연히 cost가 매우 크기 때문에 이 논문에서는 후자로 해결을 하였다.
이 propagation은 distance 기반으로 level간에 interpolation을 하는 방법인데 feature propagation level에서는 level $l-1$에 있는 point들의 feature를 level $l$에 있는 point들을 이용해 $k$NN 기반의 distance weighted interpolation을 한다. 그리고 이 feature와 set abstraction level의 feature를 skip link로 가져와서 concatenate한다. 이 feature에 1$\times$1 convolution과 유사한 unit pointnet을 사용해 기존 feature와 interpolated 된 feature를 합친다.
\[f^{(j)}(x)=\frac{\sum_{i=1}^kw_i(x)f^{(j)}_i}{\sum_{i=1}^kw_i(x)},\ where \ w_i(x)=\frac{1}{d(x,x_i)^p},\ j=1,...,C\]