paper: FlowNet3D: Learning Scene Flow in 3D Point Clouds
code: https://github.com/xingyul/flownet3d
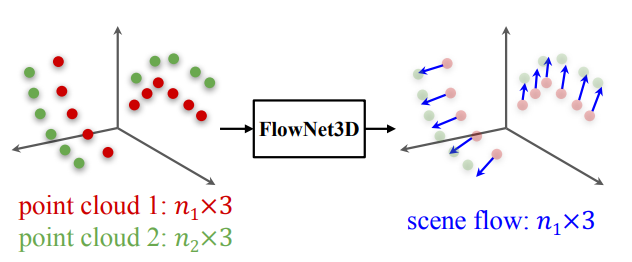
이 논문은 dynamic envorionment에서 point의 3D motion(scene flow)를 찾기 위해 제안된 논문이다. 그래서 FlowNet3D를 제안해 end-to-end로 sceneflow를 학습하였다. FlowNet3D는 두 개의 새로운 layer를 제안해 hierarchical 한 feature와 point의 motion을 representation하는 것을 배운다.
과거에 실제로 사용해봤던 논문인데 radius이내의 주변 point에 대해서만 학습을 하다보니 rotation이나 difference가 조금만 심해도 못 찾는 모습을 보였다. non rigid registration이라 볼 수 있는 알고리즘이다보니 결과가 point의 3D flow라서 SVD를 통해서 rotation을 한번 구하는 과정도 거쳐야 transformation을 구할 수 있다.
이 논문의 main contribution은 다음과 같다.
- 연속된 point cloud에서 end-to-end로 scene flow를 구할 수 있는 FlowNet3D를 제안하였다.
- 두 point cloud사이를 연관짓는 flow embedding layer와 하나의 point set에서 다른 set으로 feature를 propagating하는 set upconv layer를 제안하였다.
- Method
Problem definition
이 논문에서 풀고자 하는 문제를 정의하자면 source cloud \(P= \{ x_i|i=1,...,n_1 \}\)가 있고 target cloud \(Q= \{ y_j|j=1,...,n_2 \}\)가 있어서 $P$에 있는 모든 point가 $Q$로 scene이 바뀔때 어떤 motion을 가지는지 $P$의 point들의 motion \(D= \{ d_i|i=1,...,n_1 \}\)를 구하는 문제다.
![FlowNet3D%209bbbc7727be7427aac5517c0d961cae6/Untitled%201.png]()
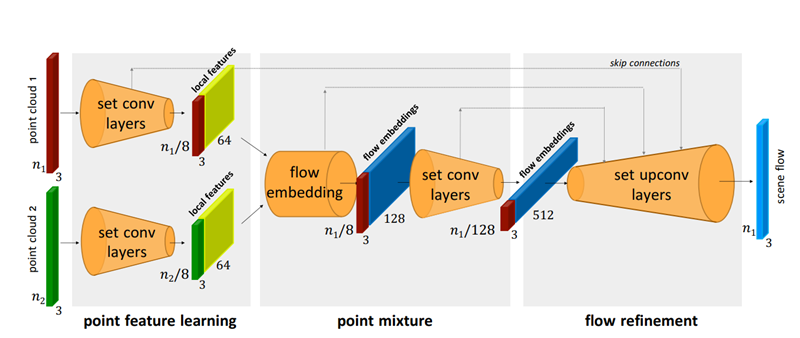
FlowNet3D Architecture
FlowNet3D는 point의 feature를 학습하고, 두 scene의 point를 합쳐서 flow embedding을 하고, flow를 모든 point로 propagating하는 3개의 key module로 이루어져 있다.
![FlowNet3D%209bbbc7727be7427aac5517c0d961cae6/Untitled%202.png]()
Hierarchical Point Cloud Feature Learning
PointNet++의 구조를 차용했으며 위의 그림의 맨 왼쪽에 해당한다. Farthest point sampling으로 centroid들을 뽑고 centroid들을 중심으로한 local coordinate값을 input으로 넣어서 feature를 추출한다. 여기서 max는 element-wise max이다.
\[f^{\prime}_j=\max\limits_{\{i|||x_i-x_j^{\prime}||\le r\}}\{h(f_i,x_i-x^{\prime}_j)\}\]Point Mixture with Flow Embedding Layer
두개의 point cloud 합쳐서 flow를 embedding하기 위해서 flow embedding layer를 제안하였으며 위의 그림의 가운데에 해당한다. 실제로는 frame $t$와 frame $t+1$ 사이에 정확한 correspondence가 존재하지 않을 수 있지만 frame $t+1$에 존재하는 point들을 이용해 weighted decision을 내리는 아이디어를 채택하여 이 layer를 고안했다.
$P$의 point를 $x_i$, feature를 $f_i$, $Q$의 point를 $y_j$, feature를 $g_j$, embed된 flow를 $e_i$라고 하고 마찬가지로 PointNet++를 사용하여 모든 $x_i$에 대해서 주변 radius이내에 존재하는 $y_j$들을 찾고 둘 사이의 difference와 $x_i$와 $y_j$의 feature를 input으로 넣어서 주변 point들의 feature의 distance를 이용해 difference 값들의 weight를 학습해서 flow를 embedding을 할 수 있도록 하였다. 여기서 max는 element-wise max이다.
\[e_i=\max\limits_{\{j|||y_j-x_i||\le r\}}\{h(f_i,g_j,y_j-x_i)\}\]그리고 이후에 set conv를 거쳐서 spatial smoothing을 하였다.
Flow Refinement with Set Upconv Layer
이 모듈은 flow embedding된 결과를 모든 point로 upsampling 하는 부분으로 이를 위해 set upconv를 제안했으며 위의 그림의 오른쪽에 해당한다.
set upconv는 set conv를 거의 그대로 사용하는데 local region sampling 방법이 다르다고 한다. FPS를 통해 뽑은 centroid 대신에 upsampling을 적용할 target point를 기준으로 한다. 단순한 3D interpolation \((f^{\prime}_j=\sum_{\{i|||x_i-x_j^{\prime}||\le r\}}w(x_i,x_j^{\prime})f_i)\) 과 비교했을때 set upconv layer에서 flow embedding layer에서 처럼 주변 feature들을 weight하는 방법을 학습을 하기 때문에 더 나은 효과를 보였다고 한다.
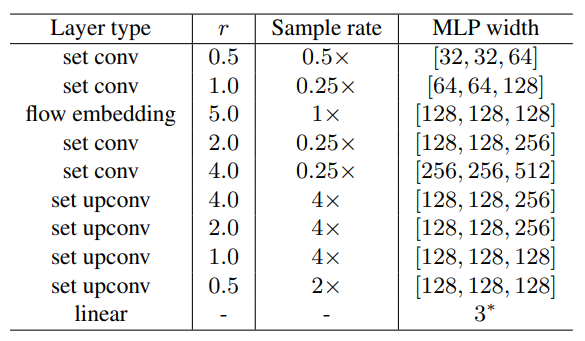
Network Architecture
![FlowNet3D%209bbbc7727be7427aac5517c0d961cae6/Untitled%203.png]()
Training loss with cycle-consistency regularization
FlowNet3D의 학습에는 smooth $L_1$ loss(huber loss)를 사용하는데 여기에 cycle-consistency regularization을 적용했다고 한다. 여기서 forward flow를 $d_i$, backward flow를 $d_i^{\prime}$, ground truth flow를 $d_i^*$라 하면 학습한 model을 이용해 forward flow와 원래의 point에 forward flow를 더한 point들에서 원래 point로 돌아가는 backward flow를 모두 구해서 loss를 다음과 같이 계산한다.
\[L(P,Q,D^*,\Theta)=\frac{1}{n_1}\sum_{i=1}^{n_1}\{||d_i-d_i^*||+\lambda||d_i^\prime+d_i||\}\]위의 loss를 통해서 ground truth와 forward flow의 차이를 줄이는 동시에 forward flow로 옮겨진 point가 다시 원래대로 돌아오는 backward flow를 구하도록 학습을 한다.
Inference with random re-sampling
Inference를 할때 FlowNet3D를 적용하는 과정중에 발생하는 down-sampling이 prediction의 noise를 발생시킬 수 있어서 이를 해결하기 위해서 random하게 resampling해서 inference를 여러번하고 그 값의 평균을 flow로 출력한다고 한다.