DiffusionDet: Diffusion Model for Object Detection
Author: Shoufa Chen Conference / Journal: Arxiv PrePrint Nickname: DiffusionDet Year: 2022
paper: DiffusionDet: Diffusion Model for Object Detection
code: GitHub - ShoufaChen/DiffusionDet: PyTorch implementation of DiffusionDet
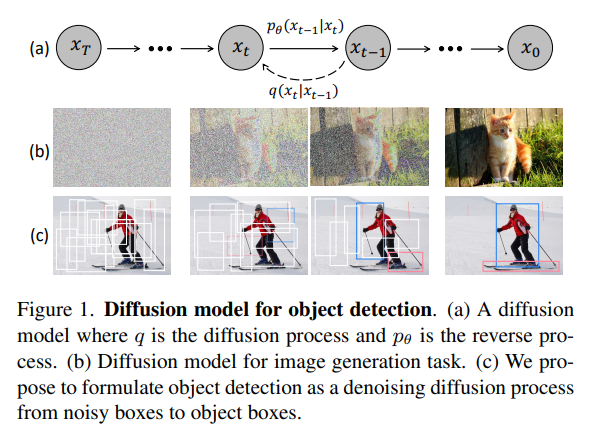
Introduction
DiffusionDet은 object detection문제를 noisy한 box를 object box로 diffusion process를 통해서 denoising하는 generation task로 새로 정의한 논문이다.
논문에서 주장하는 main contribution 및 모델의 장점
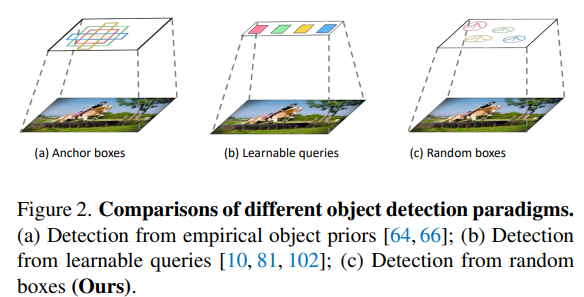
pre-define anchor, 학습된 query말고 random box도 object candidate로써의 역할을 한다는 사실을 발견했다.
![Untitled]()
- 이전의 패러다임과 완전 다르게 generative한 방식으로 object detection을 해냈다.
- Random box를 object candidate로 사용하기 때문에 train에서 사용한 random box의 수와 inference에서 사용할 random box의 수가 일치하지 않아도 된다
- Iteration을 통해서 점점 refine 되기 때문에 필요한 속도와 정확도를 맞춰서 성능을 조절할 수 있다. 즉 학습된 하나의 모델이 가지는 flexibilty가 높다고 한다.
Preliminary - Diffusion Model
Diffusion model에 대해서 아는 사람도 있겠지만 모르는 사람을 위해서 CVPR 2022 diffusion tutorial에 좋은 자료가 있어서 여기서 아주 기본적인 부분들만 가져와서 소개해봤다.
Reference: CVPR 2022 diffusion tutorial
Tutorial page: Denoising Diffusion-based Generative Modeling: Foundations and Applications

재밌어 보이는 그림이라서 가져옴 현재 generative task에서 각 model들이 표현할 수 있는 수준을 한 장으로 보여주는 그림. 왜 diffusion model이 요즘 핫한지 쉽게 이해가 됨

Diffusion Model의 motivation: 연기의 확산(diffusion)을 생각해 보면 연기가 생성되는 지점부터 쭉 퍼져나가서 모든 공간에 random하게 퍼지게 되는데 연기가 움직이는 step 하나하나를 계산하면 역으로 연기가 시작된 지점을 알 수 있듯, noisy한 image도 어떤 선명한 image로 부터 순차적으로 작은 noise가 더해져 왔으며 이 noise를 계산하면 거꾸로 noisy한 image로 부터 원래의 선명한 image를 얻을 수 있지 않겠냐는 아이디어에서 왔다.
diffusion model은 forward process와 reverse process로 나뉜다.
forward: noise를 더해가는 과정, reverse: noise를 제거해 가는 과정
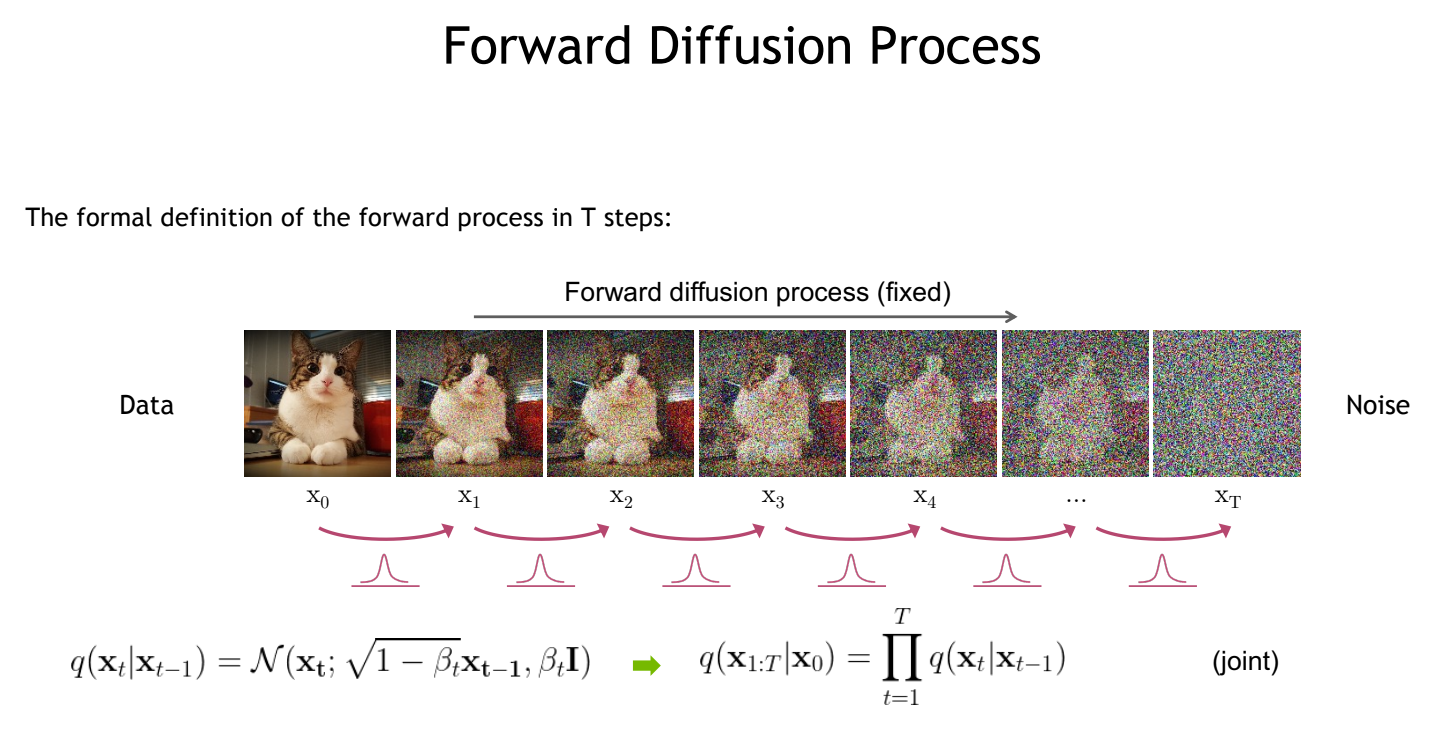
forward process: step 마다 정해진 schedule에 따라 noise를 더해 random image 생성
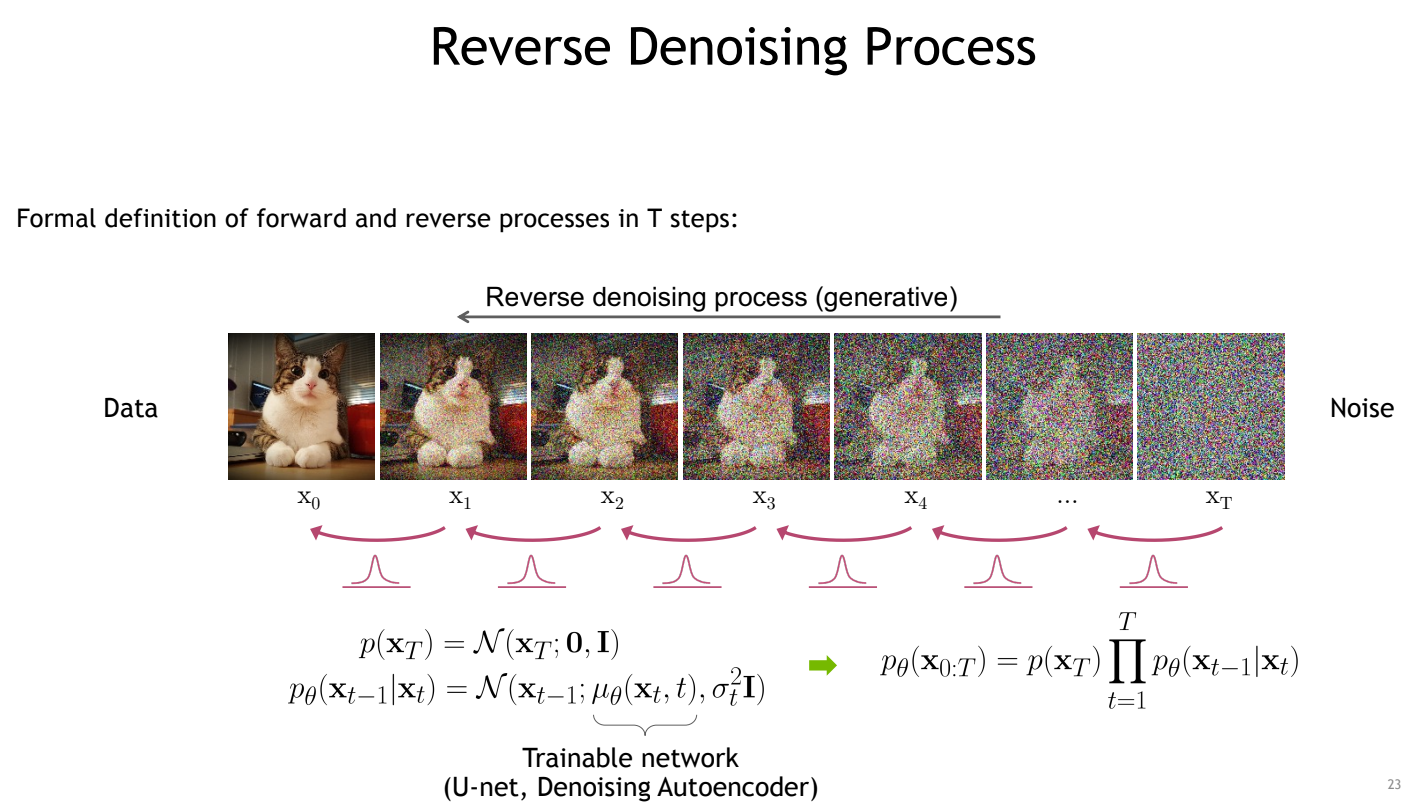
reverse process: 각 step마다 더해진 noise를 학습된 network를 이용해 predict하여 이를 역으로 계산해서 denoising을 해나감

Generation task를 할 때는 실제로 predict한 noise에서 sampling을 해서 그 값으로 denoising을 함
Method
Architecture
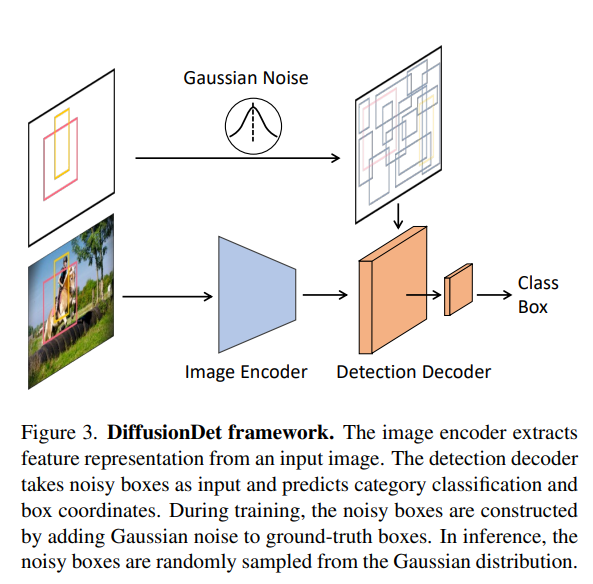
diffusion model은 iterative하게 돌아가야 하기 때문에 raw image를 사용하게 되면 computation cost가 매우 증가해서 image encoder와 detection decoder를 사용하였다. Encoder를 통해 크기가 작은 feature를 뽑고 이 feature를 이용해 diffusion process를 거치고 원하는 step에서 detection decoder를 통해서 output을 뽑는다. 결과적으로 encoder와 decoder는 한 번씩 쓰이며 raw image에 비해 빠른 속도로 diffusion process를 돌릴 수 있도록 했다.
Code Detail
- code detail은 가장 좋은 성능을 보이는 image encoder를 swin transformer를 쓴 config를 기준으로 분석하였다.
- File path:
configs/diffdet.coco.swinbase.yaml
Dataloader
Dataloader 단에서 불러오는 정보는 file_name, height, width, image_id, image, instances이다. 다른 정보는 자명하니 instances만 살펴보면 image_height, image_width, gt 정보가 들어있다. height, width와 image_height, image_width의 차이는 input으로 들어가는 size와 original image의 size의 차이 이다.
Preprocessing
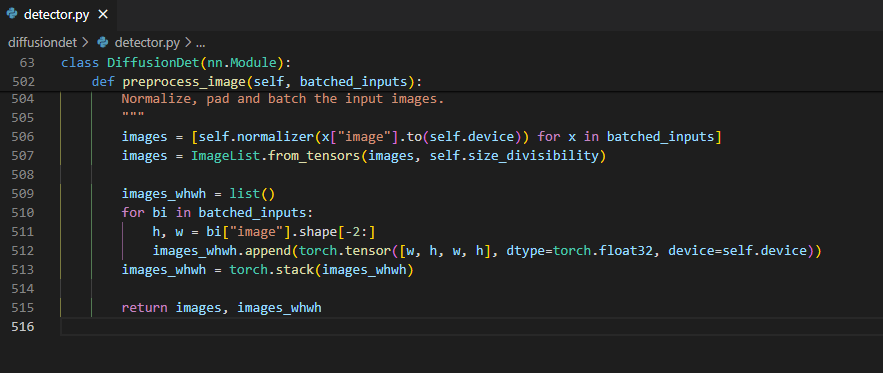
Preprocessing 단에서는 크게 복잡한 과정은 없고 images에 image를 normalize하고 batch에 속하는 image들의 크기를 32의 배수가 되도록 padding도 하고 크기도 맞춰서 저장하고 images_whwh에 image의 원래 크기를 $bs\times4$로 저장한다. 굳이 whwh로 두 번이나 저장하는 이유는 이 후에 학습과정에 사용할 box들의 $(c_x, c_y, w, h)$ 값에 편하게 곱해주기 위함이다.
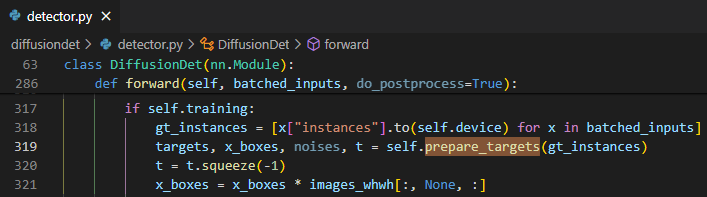
Training
전체적인 training과정은 아래와 같다.
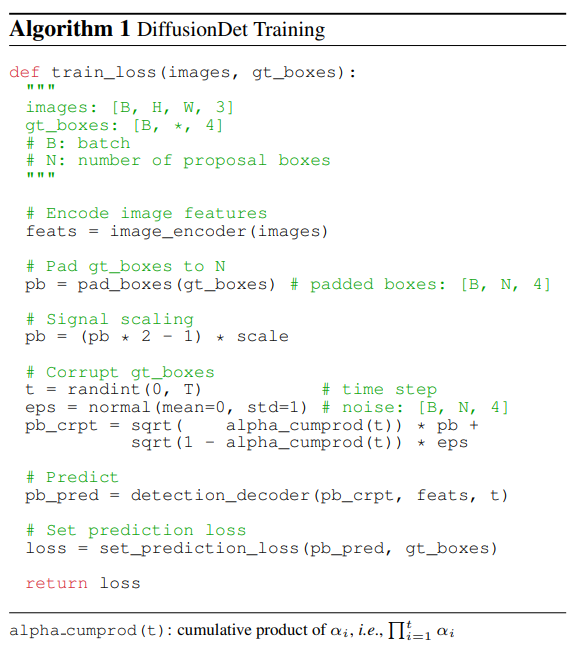
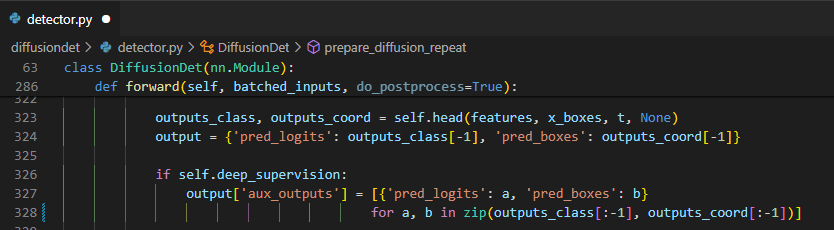
이 Pseudo code를 말로 풀어 설명하면 image에서 feature를 뽑고 gt_boxes를 train에서 사용할 random box의 수와 맞추기 위해 padding을 해준다. 그 후에 box들에 noise를 더해서 corrupt된 box 들을 얻고 이 corrupt된 box로 부터 다시 gt box를 predict하고 loss를 구한다.
코드 상에서 어떻게 구현 되었는지를 하나하나 살펴보았다.
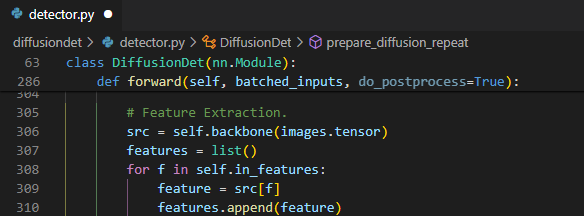
Image encoder
Image feature를 추출하는 부분이다.
![Untitled]()
swin transformer(backbone)를 사용하여 1/4, 1/8, 1/16, 1/32 크기의 feature를 뽑아
features에 저장한다.Pad gt boxes & forward process
학습에 사용할 gt data를 준비하고 forward process를 이용해 corrupted box를 생성하는 부분이다.
![Untitled]()
![Untitled]()
label 정보를 크기를 보정해서
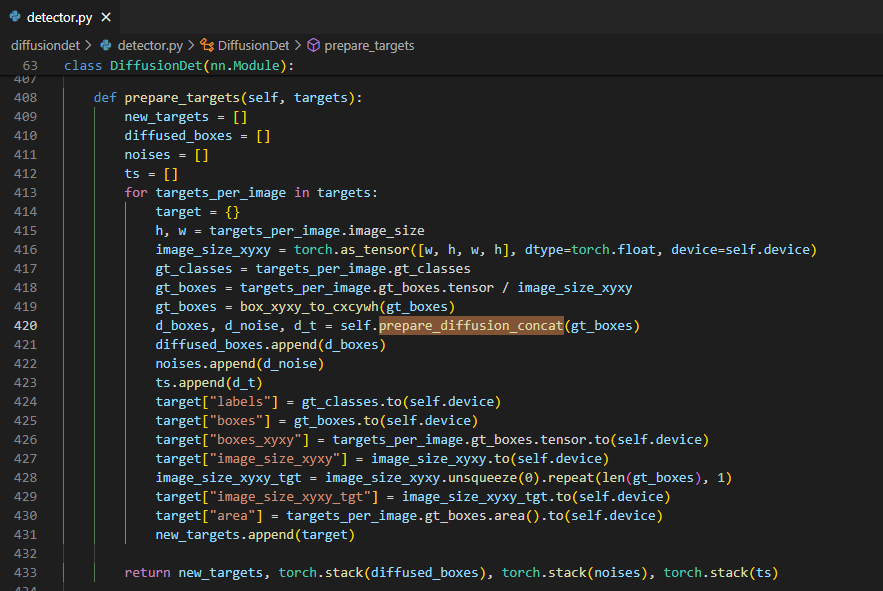
targets, noise로 corrupted된 box를x_boxes로, 사용된 noise와 step 수를noises,t로 저장한다. 여기서 noise를 어떻게 더하고 gt box padding을 하는지를 보면![Untitled]()
![Untitled]()
우선 처음에 step 수랑 noise를 random하게 생성한다.
그리고 $N_{train}$(num_proposal) 보다 gt box가 많다면 random sample을 하고 gt box가 적다면 기존 box에 약간의 noise를 더해 나머지 box를 생성한다.
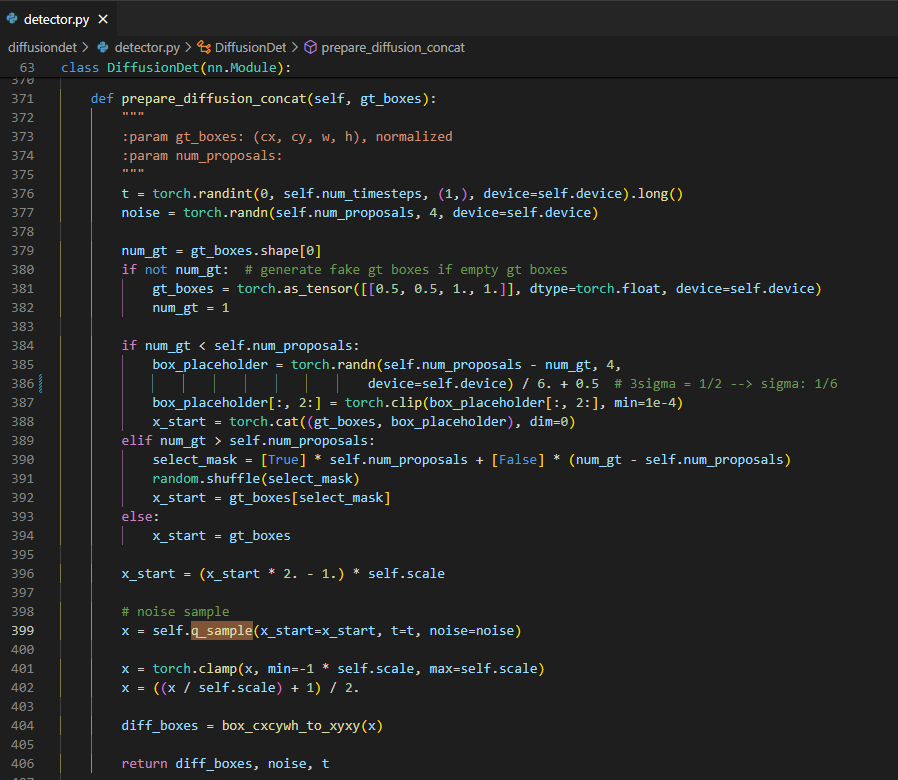
그리고 box들의 좌표를 image 중심에서 구석으로 기준점을 바꿔주고 signal scale을 곱해준다. 여기서 signal scaling을 하는 이유는 diffusion task가 이 SNR scale에 민감해서 효과적인 scale을 찾아줘야 하기 때문이며 object detection task가 generation task에 비해서 상대적으로 높은 signal scaling value에서 잘 작동하는걸 찾았다고 한다. (왜 그런지는 못 찾은 듯)
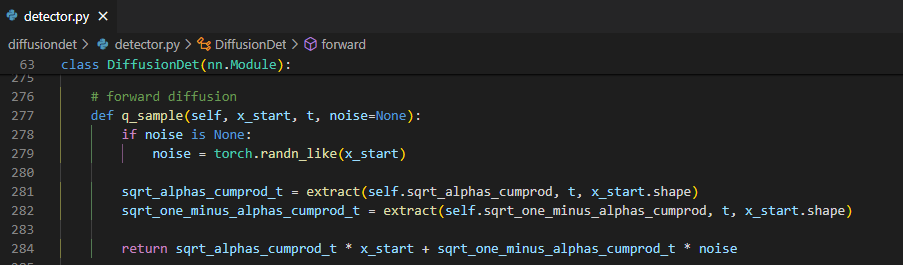
그리고 여기에 forward process에서 noise를 sample해서 더해준다. 이 forward process 함수는
q_sample인데 여기서sqrt_alphas_cumprod_t와sqrt_one_minus_alphas_cumprod_t는 t-step 까지 더해진 noise를 한번에 구하는 식인 아래의 식을 이용해 구한 것이다. 각각 mean의 변화와 variance의 변화를 의미한다. 여기서 사용된 $\alpha$는 cosine schedule을 사용했다고 한다.![Untitled]()
![Untitled]()
이렇게 구한 noise를 box의 $(c_x,c_y,w,h)$에 적용하여 box corruption을 하고 다시 image 중심 좌표계로 옮겨 준다. 이렇게 corrupt된 box와 함께 여기서 사용된 noise와 step수를 저장한다.
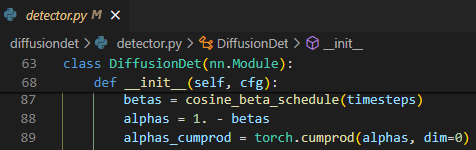
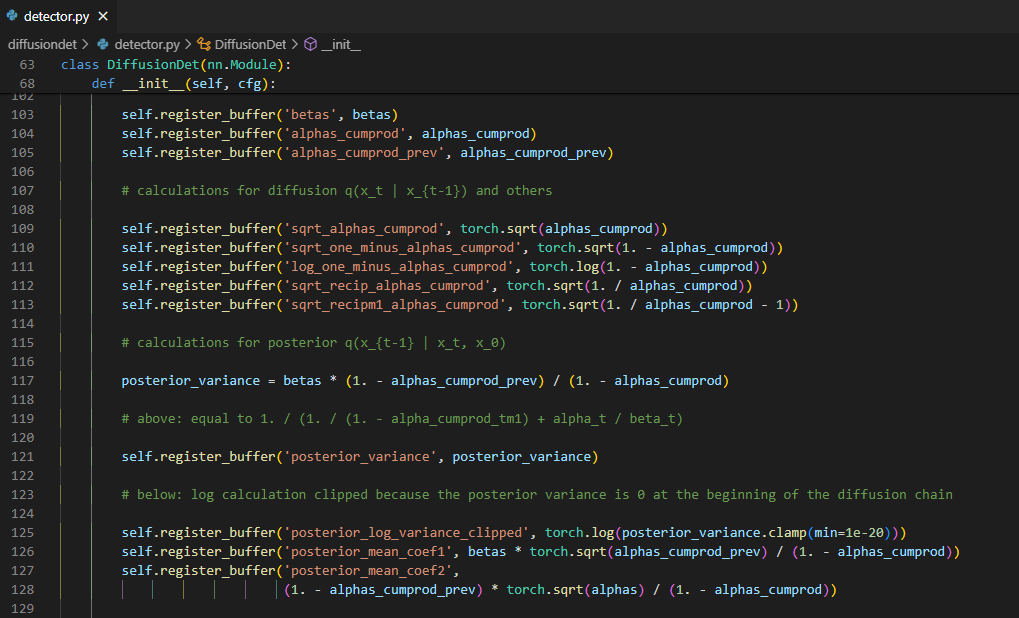
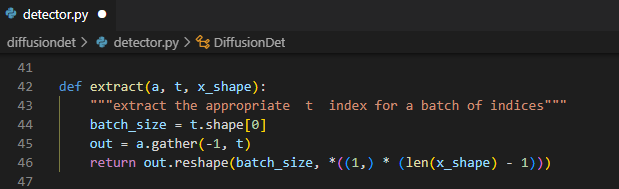
여기서 $\alpha, \beta$ 같은 parameter들은 학습되는 변수가 아닌 미리 설정한 scheduling에 따라서 정해지기 때문에
register_buffer에 미리 저장해두고extract를 통해서 가져온다.![Untitled]()
![Untitled]()
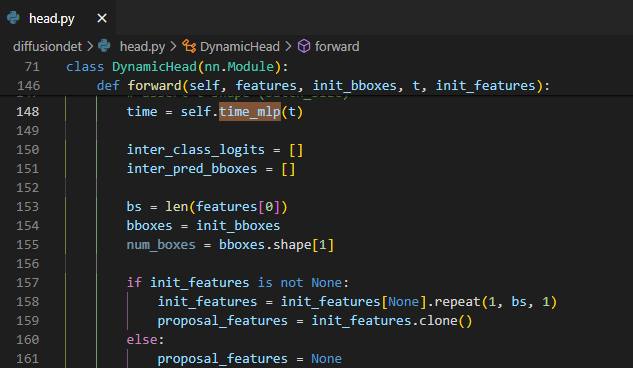
Reverse process & detection decoder
이전 단계에서 구한 noisy box와 image feature를 이용해 detection 결과를 뽑는 detection head이다.
![Untitled]()
![Untitled]()
![Untitled]()
우선
time_mlp에서 transformer의 position embedding과 유사하게 각 noise prediction마다 time step을 구분 할 수 있도록 time step을 embedding 해준다.![Untitled]()
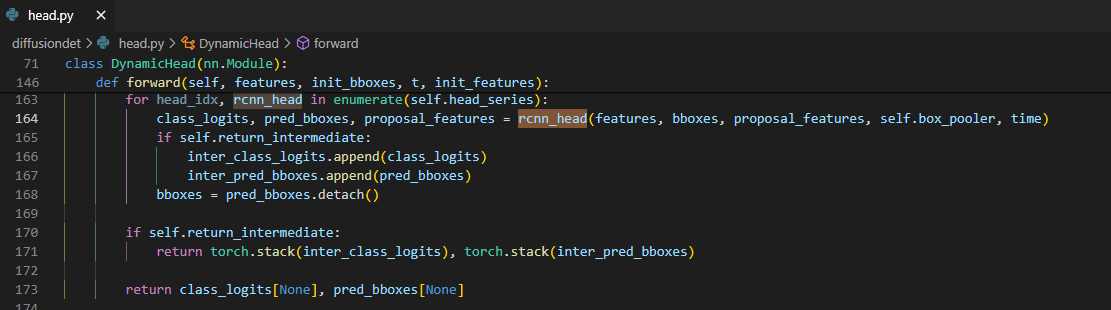
그 후에 parameter로 주는
num_heads의 수 만큼 reverse process를 적용해서 매 step 마다 predictedbboxes와proposal_features를 얻을 수 있고 이 값들은 다음 step에서도 쓰여서 결과를 refine해 나간다. 여기서 reverse process의 noise prediction을 하는데에는 Sparse R-CNN이 쓰였다![Untitled]()
![Untitled]()
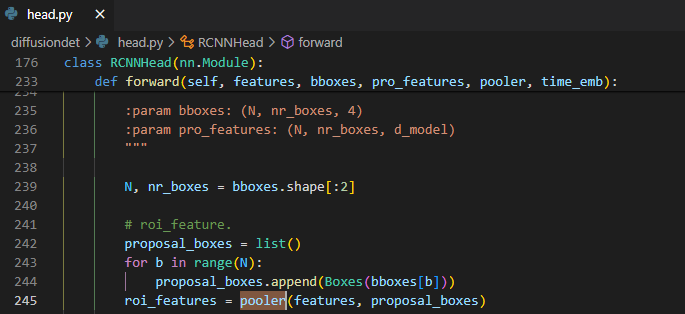
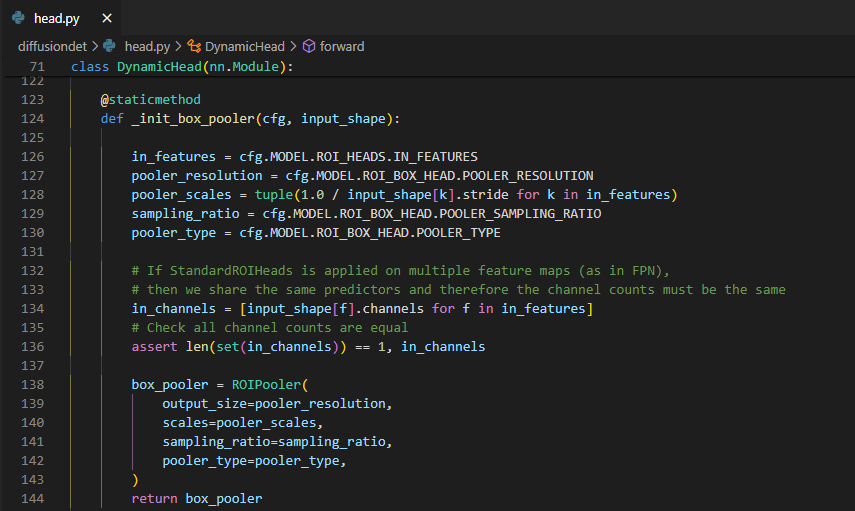
rcnn_head를 자세히 살펴보면 처음에pooler를 통해서 image backbone에서 나온 feature를 이전 step에서 구한 box를 이용해 crop하여 7x7 크기의roi_features를 구한다.![Untitled]()
feature를 denoising하는 과정(reverse process)은
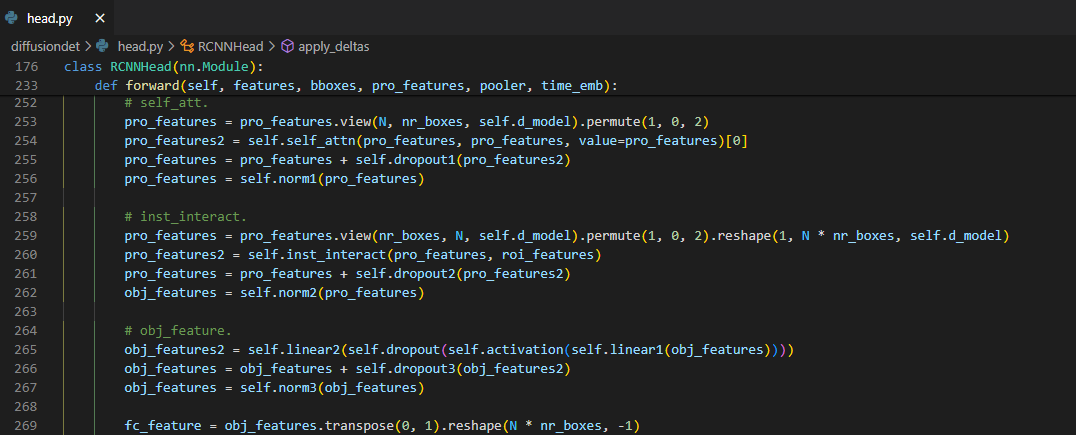
self_attention,instance_interatcion,object_feature_extraction이 세 과정을 거친다.self_attention에서는proposed_feature들 중에서 빈도가 높은 feature들을 더해주고instance_interaction을 통해 이전 단계에서 predict box 영역 내부의 feature와 유사한 feature들을 더해주고object_feature_extraction이용해 object가 존재할 확률이 높은 부분의 feature들을 더해준다.이렇게 feature들을 더해주는 과정들을 다른 diffusion model의 구현코드를 본 적이 없다면 reverse process라고 한 번에 알아볼 수 없을 수도 있다. (내가 그랬다.)
Diffusion model의 reverse process는 아래의 식과 같은데 distribution을 predict하고 여기서 sampling을 해서 denoising을 하게 되는데 실제로 predict해야 하는 부분은 mean의 noise만 predict 하면 되고 나머지 값 들은 매 time step에 따라서 미리 scheduling 되어 있다.
\[q(x_{t-1}|x_t,t_0)=\mathcal{N}(x_{t-1};\tilde{\mu}_t(x_t,x_0),\tilde\beta_t\bf{I}) \\ \text{where} \ \mu_\theta(x_t, t)=\frac{1}{\sqrt{1-\beta_t}}\left({x_t-\frac{1}{\sqrt{1-\bar{\alpha}_t}}\epsilon_\theta(x_t,t)}\right)\]각각의 과정들이 결국 noise prediction 후 denoising을 위해서 더해주는 과정과 같다고 보면 된다.
![Untitled]()
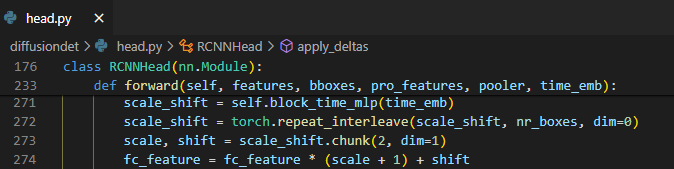
이 denoising 된 t step에서의 feature에 time step을 구분해주기 위해서 이전에 계산했던 time embedding 값에 따라서 scale, shift 해준다.
![Untitled]()
그 후에
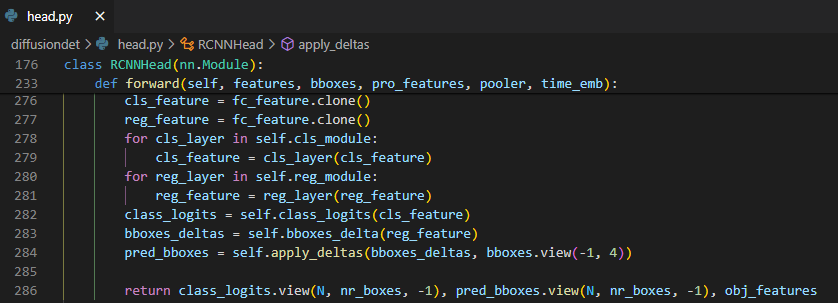
cls_layer,reg_layer를 통해서 class와 box_delta를 구해서 refine된 결과와 feature를 저장하고 지정해둔 step 수 만큼 reverse process를 반복한다. 이 코드 상에서는 6번 반복 했다.Training Loss
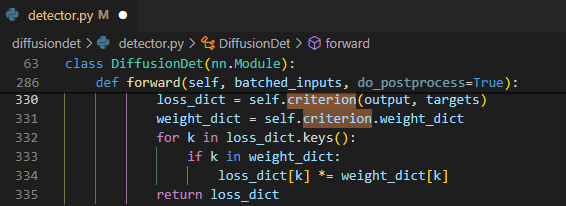
![Untitled]()
![Untitled]()
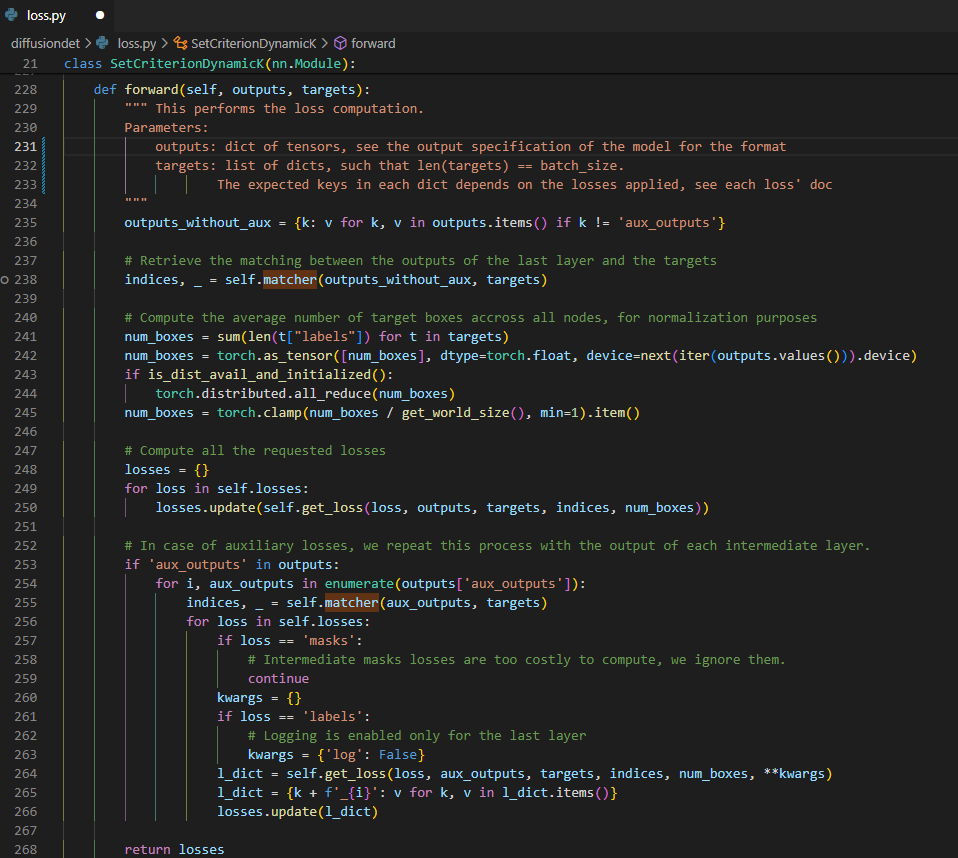
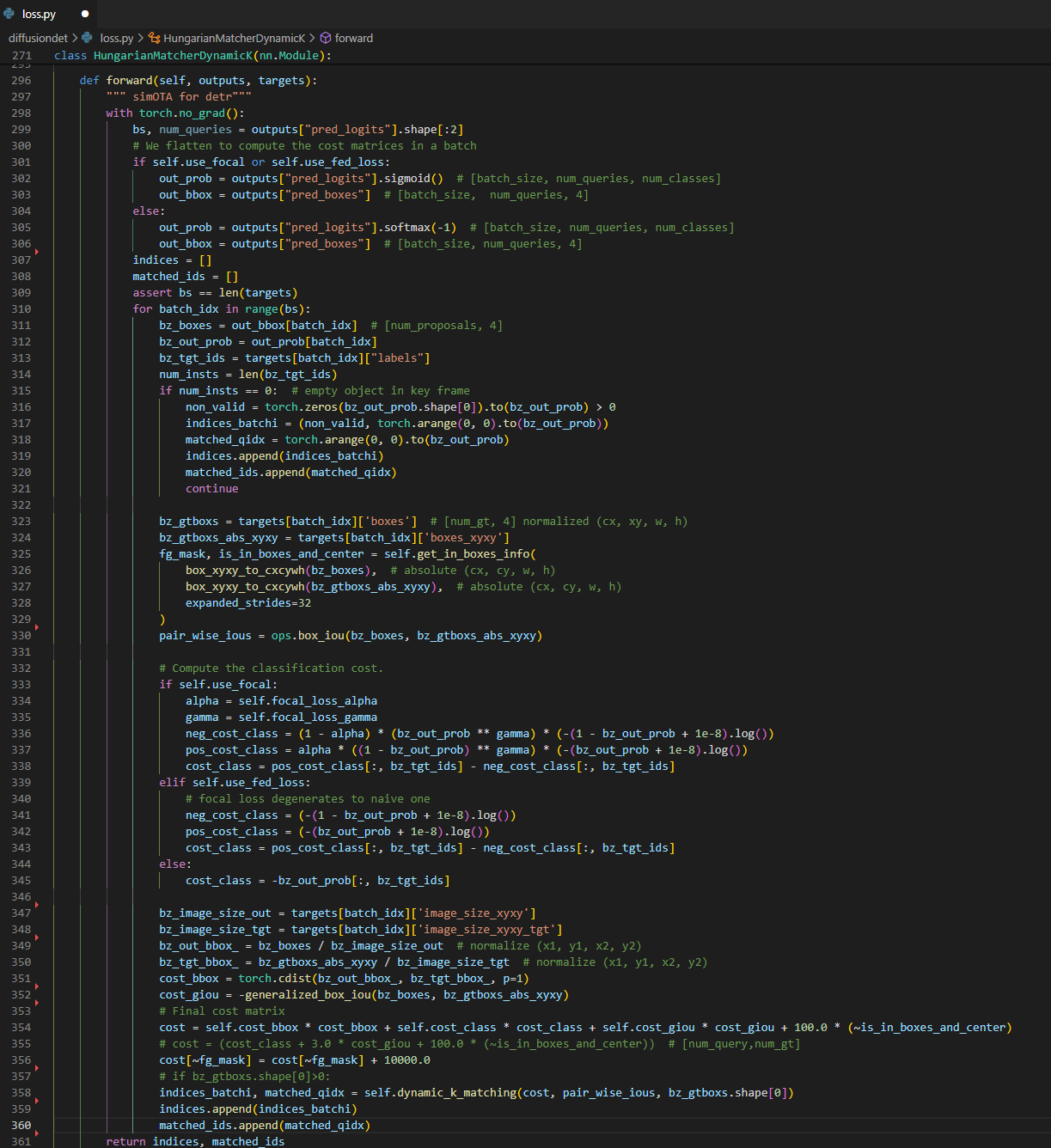
training loss는 논문에서 설명한 바에 따르면 predict한 $N_{train}$개의 box를 가지고 각각의 ground truth 마다 cost가 낮은 top-$k$개의 유사한 box들을 matching 하고 이 matching된 pair들의 loss의 평균을 사용한다. matching은 optimal transport assignment method를 사용했으며 여기서 사용한 $k=5$이다. 이 알고리즘의 자세한 설명은 이 논문의 정리와는 맞지 않는 것 같아 더 알아보고 싶다면 아래 논문과 코드 부분을 참고하면 될 것 같다.
reference paper: OTA: Optimal Transport Assignment for Object Detection
![Untitled]()
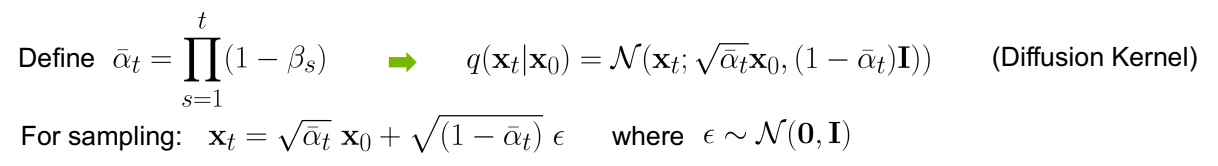

Inference
Inference 과정도 naive하게 보면 training과 크게 다르지 않으나 object detection이 정답이 정해져있는 task이다 보니 deterministic하게 generation이 이뤄져야 결과가 robust 할 것이라 기대할 수 있고 수렴 속도 향상을 위해서 inference 단의 sampling 과정에서의 diffusion process는 DDIM(Denoising Diffusion Implicit Models)을 사용한 것으로 추측된다. 해당 부분 역시 CVPR 2022 Tutorial를 참고하거나 DDIM 논문을 참고하면 될 것 같다. 직접적으로 연관된 부분은 나중에 코드와 함께 설명하겠다. 전체적인 과정의 pseudo code는 아래와 같다.

Image encoder에서 feature를 뽑고 corrupted box를 random하게 생성한다. 사용할 time step을 결정하고 detection decoder와 reverse process를 time step만큼 반복하며 box를 refine한다.
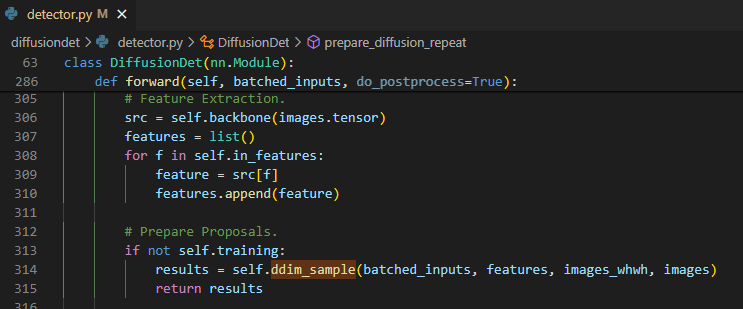
코드를 살펴보면 feature를 뽑는 과정은 특별할 것도 없고 training에서 설명 했으니 넘어가겠다. 그 후에 바로 ddim_sample 함수를 통해서 box prediction을 진행한다.
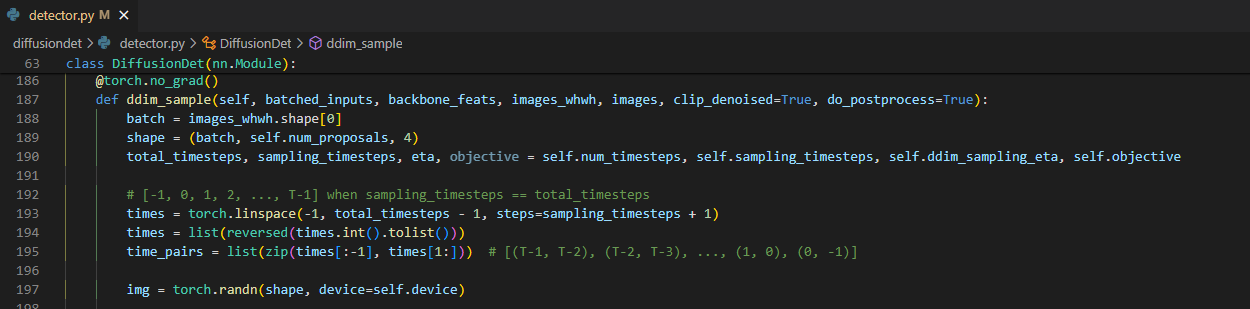
여기서는 $N_{eval}$만큼 random box를 생성하고 예측하고 싶은 time step $T$를 원하는 간격으로 쪼개서 time pair들을 생성한다. 논문에서는 $N_{eval}=500$, $T=1000$, sampling_timestep=1을 사용하였다. 총 500개의 box를 1 timestep간격으로 1000번 반복하게 되는 것이다.
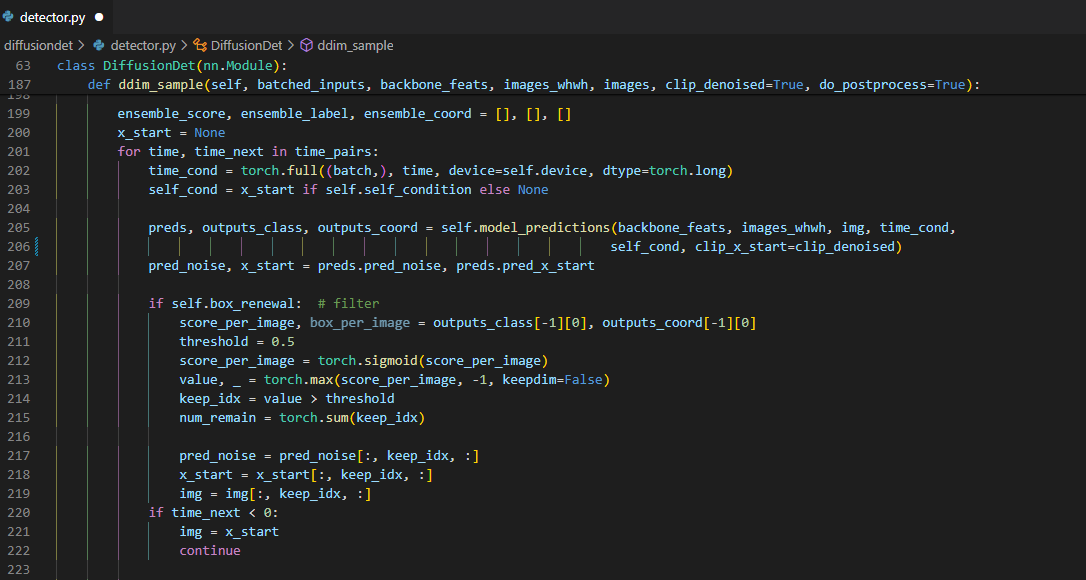
앞에서 구한 time pair들에 대해서 training에서와 같은 방식으로 model_prediction에서 reverse process를 거친다. 그 결과로 나온 predict한 box가 너무 random에 가까운 결과를 뽑은 경우에는 다음 step으로 넘겨도 크게 도움이 되지 않을 뿐더러 오히려 성능을 저해하는 요인이 될 수 있다. 그래서 box renewal에서 class score를 가지고 desired와 un-desired로 구분해서 desired로 분류된 box들만 다음 step으로 넘기는 filtering을 해준다.
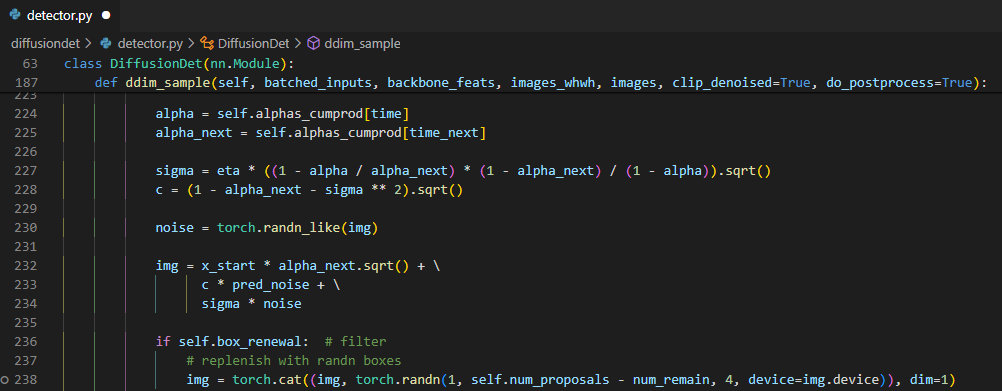
여기서 걸러낸 predicted box를 바로 사용할 수도 있으나 ddim으로 한번 reverse process를 거치면서 sampling을 해준다. ddim과 training에서 사용하던 diffusion process의 차이는 markovian process인지를 가정하는지 안 하는지의 차이이다. ddim은 non-markovian이라는 가정하에 noisy한 data의 초기상태와 바로 직전의 data의 상태를 기반으로 noise를 prediction 하기 때문에 같은 time step에서는 noisy data의 초기 상태와 1:1로 deterministic한 결과를 뽑아낼 수 있다. 이러한 특성 때문에 보다 빠르게 수렴하다보니 model_prediction의 결과로 나온 predicted box가 noisy하더라도 한번 ddim을 거치고 나면 refine된 효과를 얻을 수 있을 것으로 보여서 추가로 사용한 것으로 보인다. 논문에서도 추가로 ddim을 사용하고 안 하고의 성능차이가 꽤 있었다고 한다.
ddim에서의 reverse process 식은 아래와 같다.
\[p(\bf{x}_{t-1}|\bf{x}_t)=\mathcal{N}\left(\sqrt{\bar\alpha_{t-1}}\hat{\bf{x}}_0+\sqrt{1-\bar\alpha_{t-1}-\tilde\sigma^2_i}\cdot\frac{\bf{x}_t-\sqrt{\bar{\alpha}_t}\hat{\bf{x}}_0}{\sqrt{1-\bar\alpha_t}}, \tilde\sigma^2_i\bf{I}\right)\]여기서 위의 training section에서 언급했듯 diffusion의 time step $t$에서의 data $x_t=\sqrt{\bar\alpha_t}x_0+\sqrt{(1-\bar\alpha_t)}\epsilon$ 이므로
\[\epsilon=\frac{x_t-\sqrt{\bar\alpha_t}x_0}{\sqrt{1-\bar\alpha_t}}, x_0=\frac{x_t-\sqrt{1-\bar\alpha_t}\epsilon}{\sqrt{\bar\alpha_t}}\]이다. ddim의 reverse process식에 reparameterization trick과 위의 식을 이용하면 아래와 같은 식을 얻을 수 있다.
\[x_{t-1}=\sqrt{\bar\alpha_{t-1}}\hat{\bf{x}}_0+\sqrt{1-\bar\alpha_{t-1}-\tilde\sigma^2_i}\epsilon_\theta^t(\bf{x}_t)+\sigma_t\epsilon_t\]여기서 $\epsilon_\theta^t(\bf{x}_t)$가 predicted noise이다. 이 식을 통해서 refine된 bbox prediction 결과를 얻는다. 코드는 위의 식을 보면 이해가 될 것이다.
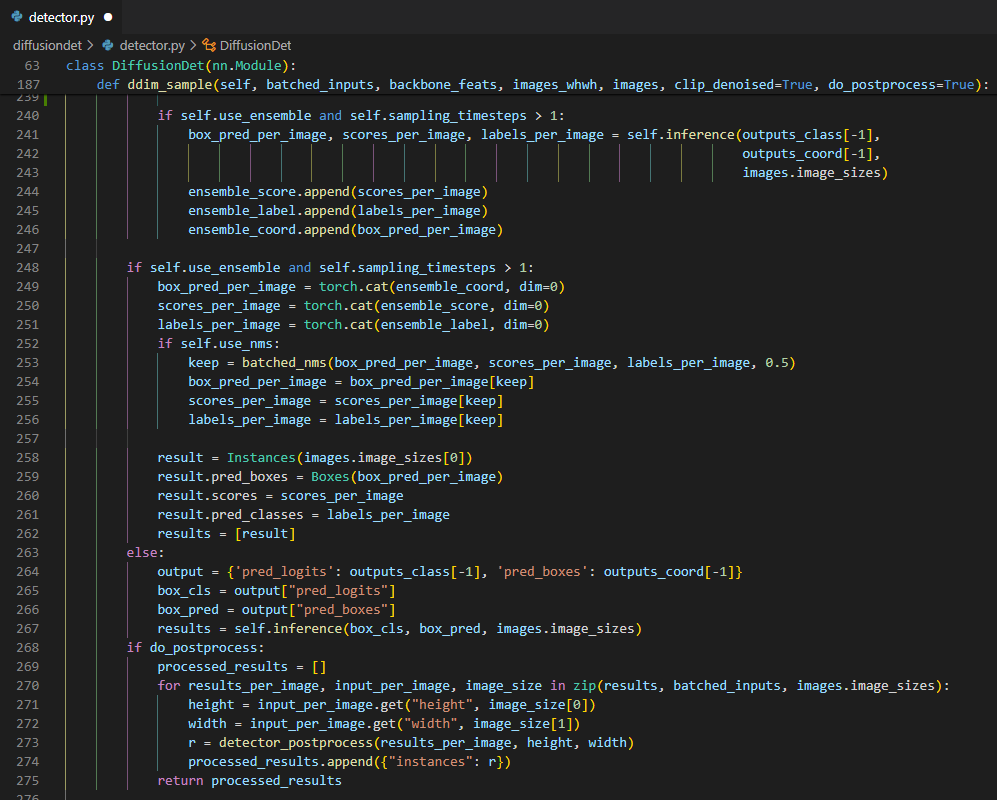
여기에 use_ensemble을 하게 되면 원래 predicted box의 결과 ddim의 결과로 나온 predicted box와 ensemble을 하게 되고 detector_postprocess를 거쳐 이미지 상에서 상대 위치로 나온 결과를 다시 절대 좌표로 바꿔서 결과를 얻게 된다.
Experiments
Results
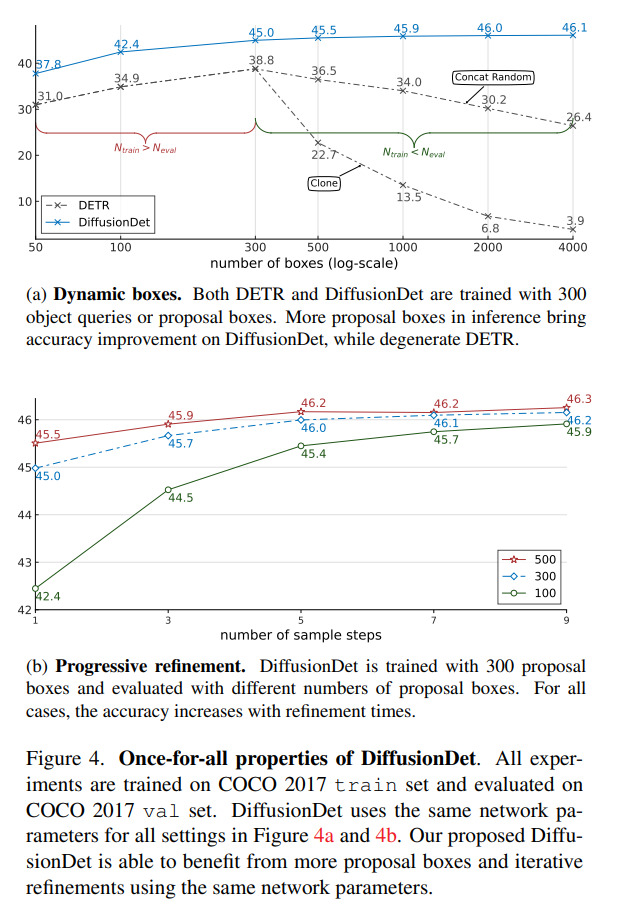
첫번째 그림은 초기에 proposal 하는 box 수에 따라서 성능을 비교한건데 DiffusionDet은 proposal box를 늘리는 만큼 성능이 올라가지만 DETR은 오히려 box의 수를 늘리면 degenration이 발생한다고 하는데 가장 성능이 좋은 box 수를 민감하게 잡아야 하는 DETR에 비해 적절하게 성능하고 속도간의 trade-off만 맞추면 되는 부분이 확실히 이점이 있는 것으로 보인다.
두번째 그림은 sample step을 거칠 수록 refinement의 효과를 보인다는 것을 나타낸 그림이다. box 수를 많이 쓰는게 overhead를 많이 잡아먹지 않는다면 step수를 늘리는 것보다 box수를 더 쓰는게 나아 보인다.
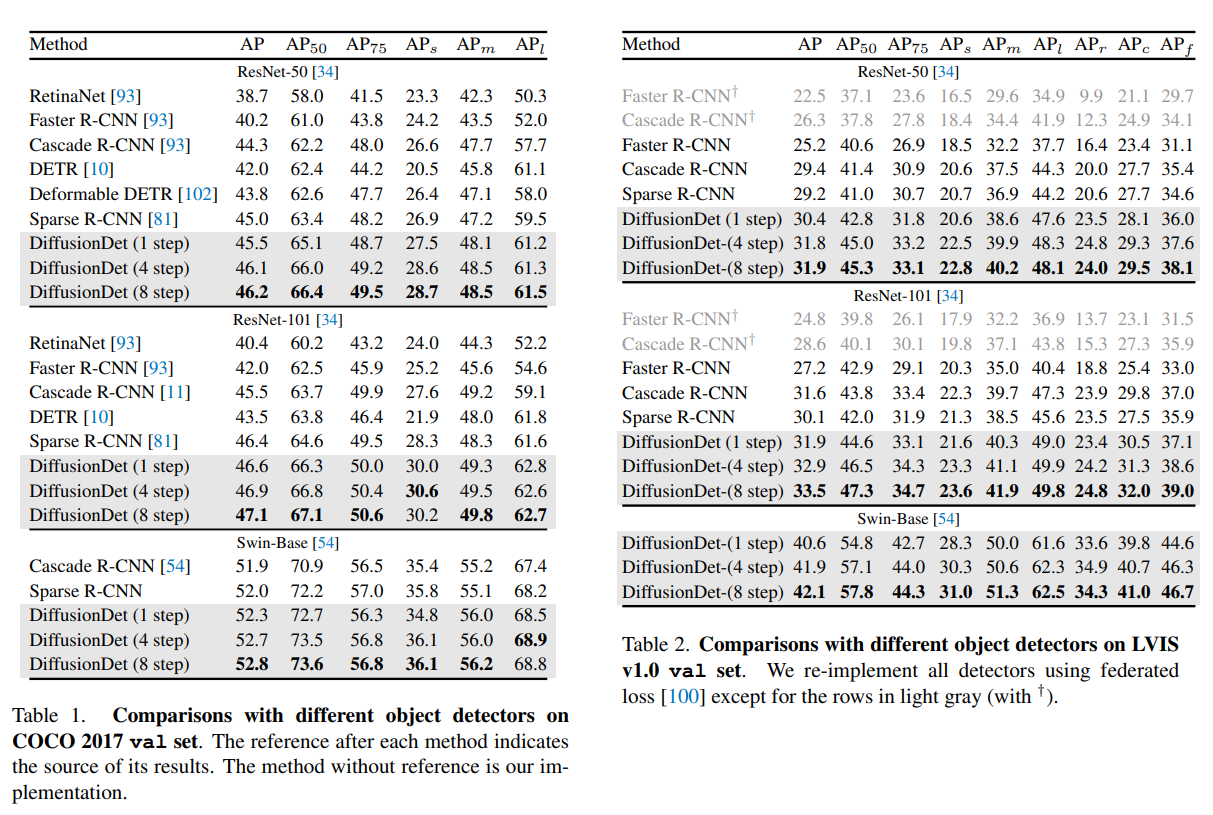
Detection 성능은 훌륭했다.
Ablation Study
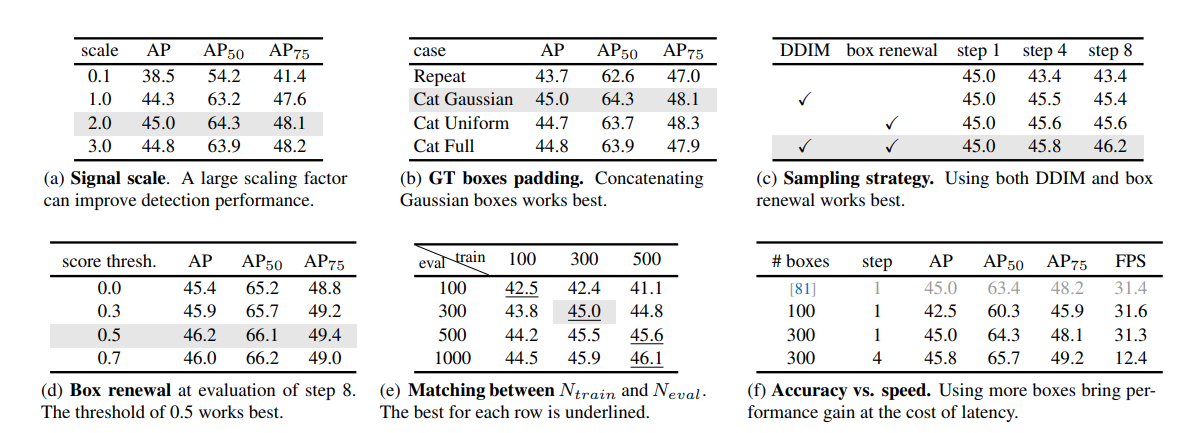
signal scale factor, box renewal thresthold, gt box padding 방법론, DDIM과 box renewal의 사용 유무, $N_{train},N_{eval}$에 따른 성능 비교를 ablation study한 결과도 같이 첨부했다. 실제 구현시에 각 요소들의 효과를 고려하는데 참고하면 좋을 것 같다.
그리고 box 수와 step 수에 따른 fpx와 정확도 차이가 나오는데 앞에서 box 수를 늘리는데에 큰 overhead가 없다면 step 수 보다는 box 수를 늘리는게 나을 것 같다고 했는데 box를 100개 쓰나 300개 쓰나 fps는 약간 느려지긴 하는데 큰 차이가 없다. 성능 향상을 위해선 box 수를 늘리는걸 우선으로 삼아도 좋을 듯 하다.
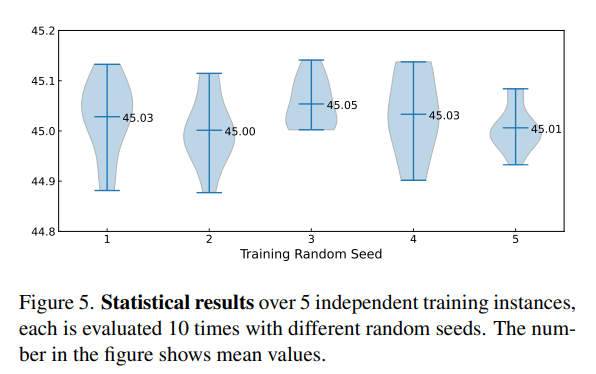
아무래도 generation model이다 보니 random seed에 따른 성능 차이에 대해서 불안감이 있을 수 있는데 이에 대해서도 테스트를 한 결과 성능이 왔다갔다 하긴 하는데 이 정도면 꽤나 robust하게 성능을 내고 있다고 봐도 무방할 정도로 편차가 크지 않게 나왔다.